


I. Introduction▲
I-A. Structure du cours▲
Le premier chapitre de ce cours traite les domaines d'application des microcontrÃīleurs embarquÃĐs, leurs caractÃĐristiques typiques et les outils de dÃĐveloppement des logiciels. Le second chapitre fournit d'importantes notions de base, qui sont essentielles à la comprÃĐhension de ce module. Le chapitre trois traite un des aspects les plus importants du dÃĐveloppement de logiciels embarquÃĐs : la conception (design). Le quatriÃĻme chapitre se concentre sur la sÃĐcuritÃĐ et la fiabilitÃĐ des systÃĻmes à microprocesseur. En effet, les erreurs logicielles dans les systÃĻmes embarquÃĐs peuvent gÃĐnÃĐrer de sÃĐrieux problÃĻmes. Le cinquiÃĻme chapitre traite de la communication dans son ensemble. Il montre, d'une part, comment les composants pÃĐriphÃĐriques peuvent Être connectÃĐs à un microcontrÃīleur embarquÃĐ et, d'autre part, comment les systÃĻmes peuvent communiquer les uns avec les autres.
Les deux thÃĻmes suivants sont explicitement exclus de ce cours bien que faisant partie du domaine de l'embarquÃĐ : RTOS (Real-Time Operating System ou SystÃĻme d'exploitation temps rÃĐel) et le serveur Web intÃĐgrÃĐ (connexion Internet de l'ÃĐquipement et la machinerie).
I-B. Domaine d'application des microcontrÃīleurs▲
Le choix du microcontrÃīleur 8 bits, 16 bits ou 32 bits dÃĐpend de la complexitÃĐ de l'application embarquÃĐe. La notion de systÃĻmes embarquÃĐs est traitÃĐe plus en dÃĐtail au chapitre IIGÃĐnÃĐralitÃĐ. Ces derniers sont essentiellement constituÃĐs d'une partie matÃĐrielle (hardware) et d'une partie logicielle (software). Leurs domaines d'applications sont les suivants :
| SystÃĻme de communication : Les microcontrÃīleurs 8 bits sont souvent utilisÃĐs pour les tÃĐlÃĐphones portables simples et la tÃĐlÃĐphonie fixe alors que les microcontrÃīleurs 32 bits se retrouvent plutÃīt dans les smartphones et les PDA. Les processeurs 8 bits ou 32 bits sont utilisÃĐs pour le raccordement des capteurs et actionneurs aux systÃĻmes de bus en fonction de la complexitÃĐ du bus et de l'application. |

|
| Technique mÃĐdicinale : Les instruments de mesure (par exemple mesure de la glycÃĐmie), les organes artificiels, etc. Selon la complexitÃĐ de l'application, microcontrÃīleurs 8 bits, 16 bits ou 32 bits. |
|
| Les technologies de la sÃĐcuritÃĐ : Les systÃĻmes pour gÃĐrer la sÃĐcuritÃĐ dans les moyens de transport (par exemple : les passages à niveau), dans les bÃĒtiments (par exemple : alarme incendie, effractions), etc. Les microcontrÃīleurs 8 bits sont utilisÃĐs en particulier dans les appareils pÃĐriphÃĐriques alors que les microcontrÃīleurs 32 bits assument les tÃĒches de contrÃīle et de gestion. |

|
| MÃĐcatronique et automation industrielle : Installation pour la production de biens, pour la logistique, etc. Les microcontrÃīleurs 8 bits sont utilisÃĐs en particulier pour les capteurs et actionneurs alors que les microcontrÃīleurs 32 bits assument les tÃĒches de contrÃīle et de gestion. |

|
| Moyens de transport : Autos, avions, vÃĐlo ÃĐlectrique, etc. |

|
| Ãlectronique de consommation : Appareil Hifi, TV, vidÃĐo, beamer, tÃĐlÃĐcommande, etc. |

|
| Application basse consommation : Les appareils à piles, tels que ceux dÃĐveloppÃĐs par la HESB pour la station ornithologique suisse, qui permettent d'enregistrer des donnÃĐes spatiales et tÃĐlÃĐmÃĐtriques. Le choix des microcontrÃīleurs se limite principalement à 8 bits en raison de la faible consommation d'ÃĐnergie et de la petite taille. Toutefois, ce dernier peut Être remplacÃĐ par un microcontrÃīleur à 16 voire 32 bits lorsque la puissance de calcul n'est pas suffisante. |

|
I-C. Les caractÃĐristiques des microcontrÃīleurs▲
La tendance actuelle est de s'ÃĐloigner de plus en plus des microcontrÃīleurs 8 bits afin de s'approcher des microcontrÃīleurs 32 bits. Les processeurs 8 bits sont utilisÃĐs dans les applications qui ont pour critÃĻres principaux la consommation et le coÃŧt. Les processeurs 16 bits sont relativement peu rÃĐpandus. Il existe nÃĐanmoins quelques exemples comme le MSP430 de TI. Le prix des processeurs 32 bits actuels, comme le Cortex-M3, est devenu tellement intÃĐressant que ces derniers remplacent de plus en plus les processeurs 8 bits.
Les processeurs 32 bits les moins chers coÃŧtent environ un euro.
Les microcontrÃīleurs 8 bits prÃĐsentent les avantages suivants faces aux microcontrÃīleurs 32 bits :
- faible consommation ;
- bas coÃŧt ;
- dimension rÃĐduite.
Les microcontrÃīleurs 32 bits prÃĐsentent les avantages suivants faces aux microcontrÃīleurs 8 bits :
- puissance et vitesse de calcul supÃĐrieures ;
- convient pour l'utilisation d'un systÃĻme d'exploitation. En effet les performances de la CPU et la taille de la mÃĐmoire sont suffisantes ;
- espace d'adressage plus grand.
Taille de mÃĐmoire requise pour les microcontrÃīleurs dans les systÃĻmes embarquÃĐs :
- la taille de la mÃĐmoire programme s'ÃĐtend typiquement de quelques kilooctets à quelques centaines de kilooctets. Cette rÃĻgle est valable pour les microcontrÃīleurs 8 et 32 bits ;
- la taille de la mÃĐmoire pour les donnÃĐes s'ÃĐtend de quelques centaines d'octets à quelques centaines de kilooctets ;
- Le portage d'un systÃĻme d'exploitation embarquÃĐ comme celui de Linux ou de Windows CE augmente considÃĐrablement l'exigence concernant la mÃĐmoire programme ou de donnÃĐes à quelques mÃĐgaoctets.
I-D. Les langages de programmation▲
I-D-1. C▲
Le langage de programmation C est la rÃĐfÃĐrence pour programmer les microcontrÃīleurs avec des exigences temps rÃĐel (voir chapitre IIGÃĐnÃĐralitÃĐ). En effet, ce dernier prÃĐsente l'avantage d'Être un langage de programmation orientÃĐ matÃĐriel. Le code machine gÃĐnÃĐrÃĐ par le compilateur est presque optimal en ce qui concerne d'une part la taille de la mÃĐmoire requise et d'autre part la vitesse d'exÃĐcution du programme. Par consÃĐquent, environ 65 % des applications embarquÃĐes sont programmÃĐes en C. Toutefois, le langage C prÃĐsente ÃĐgalement des inconvÃĐnients qui seront traitÃĐs dans la section IV.CMurphy et le langage de Programmation C de ce cours.
I-D-2. C++▲
C ++ nÃĐcessite plus de ressources (utilisation de la mÃĐmoire, la puissance du processeur) que C (environ 20 %).
Cela dÃĐpend essentiellement de comment le programme a ÃĐtÃĐ dÃĐfini en C++. Est-ce que ce dernier utilise le polymorphisme ou non ? Le ÂŦ C++ embarquÃĐ Âŧ est une version plus dÃĐpouillÃĐe du C++.
C++ prÃĐsente les avantages de la programmation orientÃĐe objet, ce qui est particuliÃĻrement intÃĐressant pour les applications plus complexes. Environ 25 % des applications embarquÃĐes sont programmÃĐes en C++.
I-D-3. Assembleur▲
Les applications programmÃĐes uniquement en assembleur sont relativement rares. Par contre, l'assembleur est souvent combinÃĐ avec du C ou du C++. Ce langage est principalement utilisÃĐ pour optimiser individuellement les fonctions. Par exemple pour les drivers (accÃĻs direct au hardware) ou les algorithmes qui nÃĐcessitent des calculs intensifs. Moins de 10 % de toutes les applications embarquÃĐes sont programmÃĐes (du moins partiellement) en assembleur.
I-D-4. Java▲
Java est aujourd'hui rarement utilisÃĐ pour programmer les applications embarquÃĐes (moins de 3 %). Java n'est pas adÃĐquat pour les applications temps rÃĐels. En effet, ce langage est interprÃĐtÃĐ (lent) et le comportement temporel du ÂŦ rÃĐcupÃĐrateur de place Âŧ (anglais : Garbage Collector) n'est pas reproductible.
I-E. Environnements et outils de dÃĐveloppement▲
Les outils CASE, les ÃĐditeurs, les compilateurs/compilateurs croisÃĐs (anglais : cross compiler) et les relieurs (anglais : linker) sont utilisÃĐs pour dÃĐvelopper les logiciels. Cette section s'intÃĐresse en particulier aux diffÃĐrentes possibilitÃĐs de dÃĐbogage qui existent dans le domaine embarquÃĐ. Les variantes suivantes sont mises à disposition en fonction des environnements de dÃĐveloppement et des types de microcontrÃīleurs :
- Simulator.
- ROM-Monitor.
- Background Debug Mode.
- Ãmulateur.
- Programmation et test direct sur ROM / Flash.
I-E-1. Simulateur▲
Le simulateur permet de tester le code sans que la partie matÃĐrielle ne soit disponible. Le comportement du microcontrÃīleur et des composants de stockage RAM / ROM est simulÃĐ sur le PC. La plupart des simulateurs permettent ÃĐgalement de commander le comportement des pins d'entrÃĐe et de sortie de façon limitÃĐe.
Les simulateurs sont souvent utilisÃĐs dans la phase de dÃĐmarrage du dÃĐveloppement, jusqu'Ã ce que les prototypes de la partie matÃĐrielle soient disponibles. Ces derniers permettent ÃĐgalement de tester les performances des algorithmes.
I-E-2. Moniteur ROM▲
Le moniteur ROM (anglais : ROM-Monitor) est la mÃĐthode plus simple pour tester une application embarquÃĐe.
Un programme moniteur (anglais : Rom-Monitor) est exÃĐcutÃĐ pour cela sur la partie matÃĐrielle. Ce dernier communique avec l'environnement de dÃĐveloppement et assure les tÃĒches suivantes :
- tÃĐlÃĐchargement du code à partir de l'environnement de dÃĐveloppement dans la RAM ;
- insertion des points d'arrÊts (anglais : break points) ;
- exÃĐcution du code pas à pas ;
- affichage du contenu des variables.
Le dÃĐsavantage du moniteur ROM rÃĐside dans le temps de calcul de la CPU et les ressources matÃĐrielles supplÃĐmentaires (mÃĐmoire, interface sÃĐrielle), qui sont nÃĐcessaires à l'exÃĐcution de ce dernier. Toutefois, le moniteur ROM est souvent utilisÃĐ Ã cause de son prix.
I-E-3. Interface JTAG▲
Certains microcontrÃīleurs possÃĻdent une interface JTAG intÃĐgrÃĐe pour dÃĐboguer (ARM par exemple / XScale).
La communication entre le PC et la platine de test est assurÃĐe par un wiggler. Ce dernier est connectÃĐ d'une part au port USB du PC (ou une autre interface comme RS232) et d'autre part à l'interface JTAG du microcontrÃīleur.
Le dÃĐbogage avec l'interface JTAG ne nÃĐcessite pas de puissance de calcul supplÃĐmentaire. Ce qui constitue incontestablement un avantage. NÃĐanmoins, les dÃĐsavantages de cette interface sont d'une part l'augmentation du prix du microcontrÃīleur (plus de silicium) et d'autre part la nÃĐcessitÃĐ de travailler avec un wiggler. En ce qui concerne les fonctionnalitÃĐs mises à disposition, l'interface JTAG se comporte comme le moniteur ROM.
I-E-4. Ãmulateur▲
Le microcontrÃīleur est remplacÃĐ par un ÃĐmulateur, qui permet de simuler ce dernier. L'ÃĐmulateur est souvent rÃĐalisÃĐ avec des versions spÃĐciales des microcontrÃīleurs, appelÃĐes puces bond out. Les ÃĐmulateurs sont chers mais ils permettent de rÃĐaliser un dÃĐbogage temps rÃĐel sans restriction.
I-E-5. Programmation et test direct de ROM / Flash▲
Les ingÃĐnieurs en gÃĐnie logiciel qui n'ont pas de ressources pour l'installation d'un environnement de test sont à plaindre. Ces derniers n'ont pas d'autre choix que de tÃĐlÃĐcharger et de tester le code à partir de la Flash. Les tests sont alors effectuÃĐs avec la fonction printf() afin d'afficher le comportement de l'application sur un terminal.
Les tests effectuÃĐs de cette maniÃĻre nÃĐcessitent en gÃĐnÃĐral beaucoup plus de temps. Par consÃĐquent, mÊme dans de petits projets, un environnement de dÃĐveloppement avec un moniteur ROM ou une interface sont rapidement rentabilisÃĐs.
II. GÃĐnÃĐralitÃĐs▲
Ce chapitre introduit des notions de base pour les systÃĻmes embarquÃĐs.
II-A. Les systÃĻmes embarquÃĐs▲
La littÃĐrature fournit pour la notion de ÂŦ systÃĻme embarquÃĐ Âŧ les dÃĐfinitions suivantes :
Laplante :
- ÂŦ A software system that is completely encapsulated. Âŧ
Douglass :
- ÂŦ âĶ the computational system exists inside a larger system to achieve its overall responsibility Âŧ
Les systÃĻmes embarquÃĐs (en anglais : embedded systems) sont composÃĐs d'une partie matÃĐrielle (hardware) et d'une partie logicielle (software). Ils sont intÃĐgrÃĐs ou embarquÃĐs dans un produit.
Ces produits sont par exemple un robot, une auto, un tÃĐlÃĐphone portable, un agenda ÃĐlectronique, une machine à cafÃĐ, etc. Le systÃĻme embarquÃĐ est en gÃĐnÃĐral responsable du contrÃīle, du traitement du signal et de la surveillance des diffÃĐrents composants du produit ou du produit dans son ensemble. La fonctionnalitÃĐ d'un systÃĻme embarquÃĐ se limite à l'exÃĐcution d'une ou quelques tÃĒches dÃĐdiÃĐes.
II-B. Les systÃĻmes temps rÃĐel▲
La littÃĐrature fournit pour la notion de ÂŦ systÃĻme temps rÃĐel Âŧ la dÃĐfinition suivante :
Laplante :
- ÂŦ A real-time system is a system that must satisfy explicit (bounded) response-time constraints or risk severe consequences, including failures. A failed system is a system which cannot satisfy one or more of the requirements laid out in the formal system specification. Âŧ
Un systÃĻme temps rÃĐel doit toujours livrer des rÃĐponses correctes dans des dÃĐlais prÃĐdÃĐfinis. Le dÃĐpassement de ces dÃĐlais se traduit par un dysfonctionnement du systÃĻme. Par consÃĐquent, dans un systÃĻme temps rÃĐel, non seulement le rÃĐsultat mais aussi l'instant auquel ce dernier est livrÃĐ sont dÃĐterminants. Remarque : la dÃĐfinition n'aborde pas le dÃĐlai en soi. Selon les types de spÃĐcification, ce dernier peut correspondre à quelques microsecondes, millisecondes voire secondes. Il est seulement important que le rÃĐsultat soit fourni à la limite de temps dÃĐfinie !
Contraintes temps rÃĐel mou/dur
Dans les systÃĻmes temps rÃĐel, on distingue souvent entre les contraintes temps rÃĐel mou et temps rÃĐel dur.
On parle de contrainte temps rÃĐel mou (souple) lorsque le systÃĻme respecte souvent la spÃĐcification temporelle mais pas toujours. Dans ce cas le comportement temporel n'est pas toujours prÃĐvisible. Les consÃĐquences de la non-conformitÃĐ sont ennuyeuses mais pas graves. Exemple : la diffusion d'un film sur un appareil portatif qui s'effectue de façon ÂŦ saccadÃĐe Âŧ.
On parle de contrainte temps rÃĐel dur lorsque le systÃĻme respecte toujours les spÃĐcifications temporelles. Le systÃĻme prÃĐsente alors un comportement temporel dÃĐterministe. L'automation industrielle et les applications liÃĐes à la sÃĐcuritÃĐ constituent les domaines typiques pour les systÃĻmes temps rÃĐel dur (ex. airbag).
RÃĐalisation des contraintes temps rÃĐel
Les conditions suivantes doivent Être remplies afin de pouvoir respecter les temps de rÃĐponse requis :
- Un design ÃĐpurÃĐ et rÃĐflÃĐchi qui prend en compte les exigences temps rÃĐel.
- Des basses latences d'interruption. Cela nÃĐcessite que :
- Les interruptions ne doivent Être dÃĐsactivÃĐes que trÃĻs briÃĻvement.
- Les routines de service d'interruption doivent Être aussi courtes que possible.
- Un code compact et rapide. Cela affecte ÃĐgalement le choix du langage de programmation (C-Code, ÃĐgalement C++ en fonction de la CPU, ÃĐventuelles optimisations des points critiques en assembleur).
- Des tests approfondis qui tiennent compte de toutes les situations et conditions possibles. La capacitÃĐ temps rÃĐel est trÃĻs difficile à dÃĐmontrer !
II-C. Le processus technique▲
Ce terme apparaÃŪt principalement dans le cadre d'automation industrielle. Voici une brÃĻve synthÃĻse :
| DÃĐfinitions du ÂŦ processus Âŧ selon DIN 6620 : Un processus est une transformation/transport de matiÃĻre/ÃĐnergie/information. L'ÃĐtat du processus technique peut Être mesurÃĐ, contrÃīlÃĐ et gÃĐrÃĐ par des moyens techniques. |
La figure suivante montre l'interface entre un systÃĻme embarquÃĐ et un processus technique. Selon les applications, le systÃĻme embarquÃĐ peut Être ÃĐquipÃĐ d'une interface utilisateur ou d'une connexion à d'autres systÃĻmes :

Le processus technique est la source et la destination des donnÃĐes techniques. Le systÃĻme embarquÃĐ lit l'ÃĐtat du processus à l'aide des capteurs et il influence cet ÃĐtat à l'aide des actionneurs, du point de vue du systÃĻme embarquÃĐ.
Exemples de capteur :
- interrupteur mÃĐcanique, inductif ou optique ;
- convertisseur A/D ;
- sonde de tempÃĐrature, sonde de pression.
Exemples d'actionneur :
- soupape ;
- moteur ;
- ÃĐcran, LED ;
- relais ;
- convertisseur D/A ;
La figure suivante montre en dÃĐtail les transferts de donnÃĐes entre l'ordinateur temps rÃĐel et le processus technique.
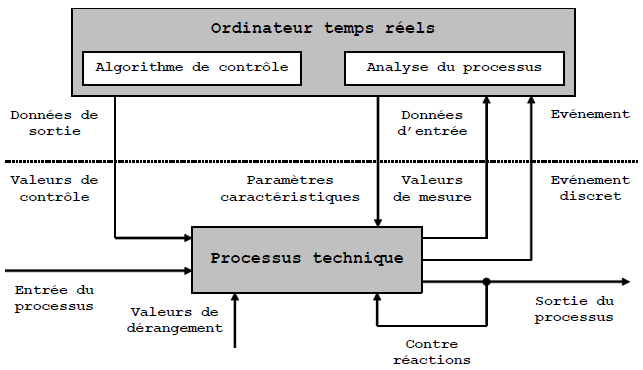
Le processus technique possÃĻde des entrÃĐes et des sorties, qui peuvent Être soit de l'information, soit du matÃĐriel.
Les contre-rÃĐactions ou les valeurs de dÃĐrangement influencent ÃĐgalement le processus technique. Des paramÃĻtres caractÃĐristiques peuvent Être transmis au processus technique.
L'ordinateur temps rÃĐel analyse le processus technique en lisant les valeurs de mesure à des instants prÃĐcis, qui sont dÃĐfinis par les occurrences des ÃĐvÃĐnements. Les algorithmes de contrÃīle permettent alors de dÃĐfinir des valeurs de contrÃīle afin d'assurer le fonctionnement correct du processus technique.
II-D. Les systÃĻmes de communication industriels▲
II-D-1. La structures des systÃĻmes de production industriels▲
Des systÃĻmes industriels sont souvent organisÃĐs de maniÃĻre hiÃĐrarchique. Dans la figure suivante, nous trouvons un exemple simple et trÃĻs gÃĐnÃĐral :
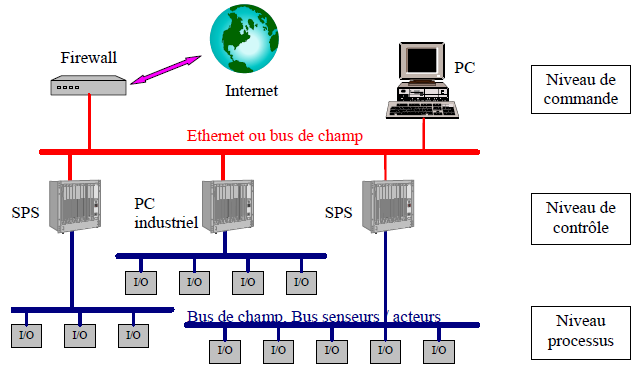
Un systÃĻme industriel consiste en plusieurs calculateurs et/ou systÃĻmes imbriquÃĐs sur diffÃĐrents niveaux hiÃĐrarchiques. De plus, il y a un ou plusieurs systÃĻmes de communication pour ÃĐchanger les donnÃĐes.
Le systÃĻme reprÃĐsentÃĐ Ã la Figure 3 a ÃĐtÃĐ partagÃĐ en trois niveaux, qui possÃĻdent les tÃĒches suivantes :
Niveau de commande :
- Ce niveau est responsable de l'analyse des donnÃĐes systÃĻmes (coordination et planification), qui est essentiellement rÃĐalisÃĐe avec des microprocesseurs 32 et 64 bits.
Niveau de contrÃīle :
- Les diffÃĐrents processus techniques sont contrÃīlÃĐs ou gÃĐrÃĐs (systÃĻme asservi) Ã ce niveau. On se sert de microcontrÃīleurs 32 bits ou de microprocesseurs.
Niveau processus :
- Sur ce niveau, on trouve les capteurs qui lisent les donnÃĐes processus, ainsi que les acteurs qui influencent directement le processus. Des microcontrÃīleurs 8 bits sont utilisÃĐs principalement à ce niveau. Toutefois, des microcontrÃīleurs 32 bits sont de plus en plus utilisÃĐs à ce niveau. En effet les prix de ce type de processeur ont fortement diminuÃĐ alors que les exigences pour la communication entre les diffÃĐrents nÅuds ont augmentÃĐ.
Suivant la complexitÃĐ du systÃĻme, on a ÃĐgalement plus de trois niveaux. Souvent ce sont :
- niveau de contrÃīle d'entreprise ;
- niveau de finition ;
- niveau d'installation ;
- niveau cellulaire ;
- niveau de champ ;
- niveau processus.
II-D-2. Les critÃĻres pour la communication▲
Les critÃĻres pour la transmission de lâinformation dans un systÃĻme de production industriel, comme celui dÃĐcrit au chapitre II.D.1La structures des systÃĻmes de production industrielle peuvent varier considÃĐrablement. En effet ces derniers dÃĐpendent d'une part de l'application et d'autre part du niveau hiÃĐrarchique. Les principaux critÃĻres sont les suivants :
- capacitÃĐ temps rÃĐel pour les niveaux processus et contrÃīle ;
- taux de transfert ;
- standards industriels / degrÃĐ d'utilisation ;
- fonctionnalitÃĐ ;
- tolÃĐrance erreurs / fiabilitÃĐ / immunitÃĐ contre des perturbations ;
- ÃĐconomie (optimisation des coÃŧts).
Les deux critÃĻres les plus importants sont la capacitÃĐ temps rÃĐel et le taux de transfert. Ces derniers sont illustrÃĐs graphiquement à l'aide de pyramide de communication :
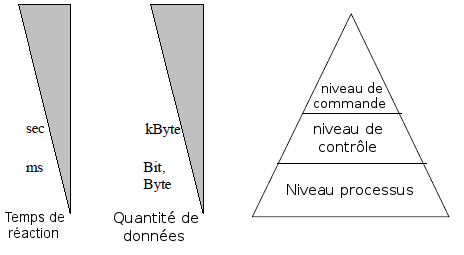
Le chapitre VConnexion de la pÃĐriphÃĐrie aborde certains systÃĻmes de communication plus en dÃĐtail.
III. MÃĐthodes de conception▲
La fonctionnalitÃĐ d'un systÃĻme peut toujours Être dÃĐcomposÃĐe en sous-fonctions (modularisation). Il existe plusieurs stratÃĐgies pour exÃĐcuter ces sous-fonctions (ex. : dÃĐroulement cyclique, RTOS, etc.). Les diffÃĐrentes approches sont discutÃĐes dans les sections suivantes. Il est crucial d'analyser le dÃĐroulement du programme durant la phase de conception afin de pouvoir dÃĐfinir une structure adÃĐquate pour ce dernier.
III-A. DÃĐroulement cyclique▲
Toutes les fonctions du programme sont exÃĐcutÃĐes l'une aprÃĻs l'autre dans l'approche cyclique. Lorsque la derniÃĻre fonction du cycle a ÃĐtÃĐ exÃĐcutÃĐe, le programme continue avec l'exÃĐcution de la premiÃĻre fonction de ce dernier. L'intervalle de temps nÃĐcessaire pour exÃĐcuter un cycle entier dÃĐpend essentiellement du temps requis pour exÃĐcuter ses diffÃĐrentes fonctions.
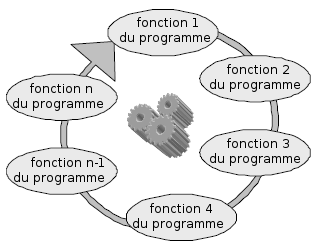
La programmation de l'approche cyclique est relativement simple. Les fonctions sont appelÃĐes l'une aprÃĻs l'autre dans la boucle principale de la fonction main(). Les ÃĐvÃĐnements (par exemple, l'actionnement d'un commutateur ou la rÃĐception de donnÃĐes via l'interface sÃĐrie) sont scrutÃĐs pÃĐriodiquement dans cette boucle (anglais : polling). NÃĐanmoins, les spÃĐcifications pour les applications embarquÃĐes exigent souvent que les ÃĐvÃĐnements soient traitÃĐs dans un dÃĐlai trÃĻs court, ce qui n'est pas forcÃĐment possible avec l'approche cyclique dÃĐcrite ici.
III-B. DÃĐroulement quasi parallÃĻle et ÃĐvÃĐnementiel▲
Les ÃĐvÃĐnements peuvent interrompre le processus cyclique en dÃĐclenchant une interruption. La routine de service d'interruption (abrÃĐviation en anglais : ISR) est ainsi appelÃĐe en temps rÃĐel pour traiter l'ÃĐvÃĐnement. Le dÃĐroulement du programme devient ainsi quasi parallÃĻle et ÃĐvÃĐnementiel.
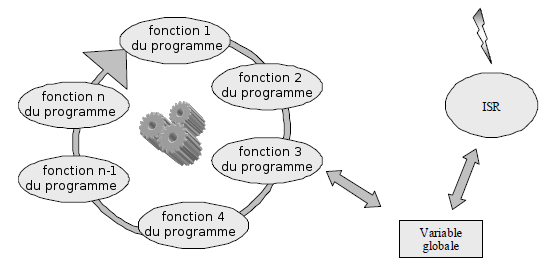
Cette approche est souvent utilisÃĐe dans les systÃĻmes embarquÃĐs. En effet, les interruptions sont relativement faciles à programmer. Les critÃĻres temps rÃĐel du systÃĻme sont ainsi bien remplis. NÃĐanmoins, il subsiste le problÃĻme de la communication entre l'ISR et les fonctions de la boucle principale. En effet, cette communication nÃĐcessite le recours aux variables globales. Il est important d'exclure les accÃĻs mutuels à ce genre de variable de sorte qu'une partie du programme ne puisse y accÃĐder à un instant donnÃĐ. Cela signifie qu'une fonction de la boucle principale doit verrouiller l'interruption (dont la routine de service pourrait ÃĐgalement accÃĐder à cette variable) durant l'accÃĻs à cette variable. Pour des applications plus complexes, qui nÃĐcessitent plusieurs interruptions et variables globales, cela peut conduire à des interdÃĐpendances dissimulÃĐes et entraÃŪner des crashs du systÃĻme. Des exemples pour ce genre de problÃĻme, qui peuvent engendrer des conditions dites de course, sont fournis à la section IV.C.6Les conditions de course.
III-C. DÃĐroulement quasi parallÃĻle avec RTOS▲
Les applications embarquÃĐes plus complexes sont souvent rÃĐalisÃĐes avec des systÃĻmes d'exploitation temps rÃĐel (abrÃĐviation anglaise : RTOS). Bien que ces systÃĻmes nÃĐcessitent plus de ressources que l'approche quasi parallÃĻle et ÃĐvÃĐnementielle, ils offrent nÃĐanmoins des outils supplÃĐmentaires pour rÃĐsoudre les problÃĻmes dÃĐcrits dans la section prÃĐcÃĐdente. Les RTOS ne sont pas traitÃĐs dans ce cours.
III-D. State-Event▲
III-D-1. Introduction▲
Le comportement de la plupart des systÃĻmes techniques peut Être dÃĐcrit avec des machines d'ÃĐtat (anglais : State Machine). Ce chapitre traite la conception d'une machine d'ÃĐtat à l'aide de diagramme d'ÃĐtat et sa programmation en C. Les exemples illustratifs se basent sur une connexion tÃĐlÃĐphonique simplifiÃĐe.
Les systÃĻmes techniques possÃĻdent un nombre fini d'ÃĐtats, dans lequel ils peuvent se trouver à un instant donnÃĐ. Ils rÃĐagissent à des ÃĐvÃĐnements qui peuvent se produire durant leur fonctionnement. En fonction de l'ÃĐtat actuel du systÃĻme, ces ÃĐvÃĐnements peuvent dÃĐclencher des activitÃĐs et ÃĐventuellement gÃĐnÃĐrer un changement d'ÃĐtat de ce dernier.
DÃĐfinitions :
- Un ÃĐtat (state) est une disposition, dans laquelle le systÃĻme entre durant une pÃĐriode limitÃĐe. DiffÃĐrentes activitÃĐs (activity) peuvent Être exÃĐcutÃĐes au sein d'un ÃĐtat. Exemples d'ÃĐtat : ÂŦ Sonnerie Âŧ, ÂŦ Conversation Âŧ, etc.
- Un ÃĐvÃĐnement (event) est une influence extÃĐrieure sur le systÃĻme ou un changement dans le systÃĻme. Un ÃĐvÃĐnement est de courte durÃĐe (quantitÃĐ de temps nÃĐgligeable) et a toujours un impact sur le systÃĻme. Exemples d'ÃĐvÃĐnements : ÂŦ combinÃĐ est dÃĐcrochÃĐ Âŧ, ÂŦ numÃĐro est sÃĐlectionnÃĐ Âŧ, etc.
- Une transition dÃĐcrit le passage d'un ÃĐtat à un autre. Une transition est toujours dÃĐclenchÃĐe par un ÃĐvÃĐnement. Exemple de transition : Le dÃĐcrochement du combinÃĐ (ÃĐvÃĐnement) change l'ÃĐtat du systÃĻme de ÂŦ TÃĐlÃĐphone libre Âŧ à ÂŦ Saisir le numÃĐro Âŧ.
- Une action est exÃĐcutÃĐe au cours d'une transition. La transition ÂŦ TÃĐlÃĐphone libre Âŧ Ã ÂŦ Saisir le numÃĐro Âŧ augmente la tonalitÃĐ.
III-D-2. Conception▲
III-D-2-a. Tableau d'ÃĐtats▲
Les tableaux d'ÃĐtats constituent un moyen simple mais pas trÃĻs comprÃĐhensifs de dÃĐcrire les ÃĐtats d'un systÃĻme. Tous les ÃĐtats, ÃĐvÃĐnements, actions et les transitions sont dÃĐfinis sous forme texte dans un tableau. Les tableaux d'ÃĐtats permettent de dÃĐcrire entiÃĻrement le comportement d'un systÃĻme.
| Ãtat actuel | ÃvÃĐnement | Action | Nouvel ÃĐtat |
|---|---|---|---|
| TÃĐlÃĐphone libre | CombinÃĐ est dÃĐcrochÃĐ | Activer la tonalitÃĐ bip | Saisir le numÃĐro |
| Saisir le numÃĐro | CombinÃĐ est raccrochÃĐ | Pause | TÃĐlÃĐphone libre |
| Chiffre est sÃĐlectionnÃĐ | Transmettre le chiffre | Saisir le numÃĐro | |
| NumÃĐro libre est sÃĐlectionnÃĐ | Activer la tonalitÃĐ d'appel | Sonnerie | |
| NumÃĐro occupÃĐ est sÃĐlectionnÃĐ | Activer la tonalitÃĐ occupÃĐe | OccupÃĐ | |
| Sonnerie | CombinÃĐ est dÃĐcrochÃĐ | Pause | TÃĐlÃĐphone libre |
| Correspondant s'annonce | - | Conversation | |
| OccupÃĐ | CombinÃĐ est raccrochÃĐ | Pause | TÃĐlÃĐphone libre |
| Conversation | CombinÃĐ est raccrochÃĐ | Pause | TÃĐlÃĐphone libre |
III-D-2-b. Diagramme d'ÃĐtat▲
Les diagrammes d'ÃĐtat permettent de reprÃĐsenter les diffÃĐrents ÃĐtats et transitions du systÃĻme sous forme graphique. Par consÃĐquent, ces derniers sont beaucoup plus comprÃĐhensifs que les tableaux d'ÃĐtats. Il existe diffÃĐrentes approches pour la reprÃĐsentation graphique. Ce cours se base sur le standard UML (V2.0), avec lequel deux ÃĐtats et une transition seront reprÃĐsentÃĐs de la maniÃĻre suivante :

Les ÃĐtats sont reprÃĐsentÃĐs par des rectangles arrondis qui contiennent leur nom. Les activitÃĐs, qui sont exÃĐcutÃĐes dans un ÃĐtat donnÃĐ, sont indiquÃĐes en dessous du nom.
Les transitions sont indiquÃĐes par des flÃĻches entre les ÃĐtats. Une transition est exÃĐcutÃĐe lorsqu'un ÃĐvÃĐnement se produit et que la condition requise se rÃĐalise. Une action peut Être ÃĐgalement dÃĐfinie pour les transitions.
La dÃĐfinition des actions, des conditions et des activitÃĐs est en option.
Notre exemple d'appel tÃĐlÃĐphonique peut Être reprÃĐsentÃĐ de la maniÃĻre suivante avec un diagramme d'ÃĐtat :
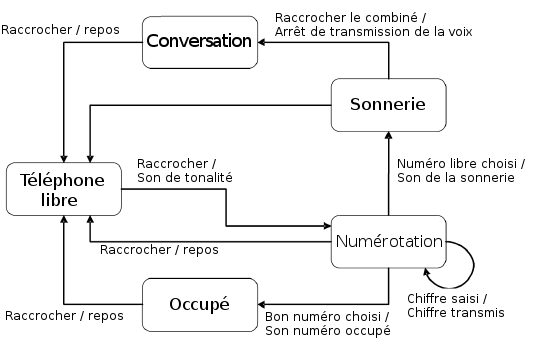
Les diagrammes d'ÃĐtat peuvent ÃĐgalement Être imbriquÃĐs l'un dans l'autre. Cela est particuliÃĻrement utile quand, comme ci-dessus, les mÊmes ÃĐvÃĐnements (CombinÃĐ est raccrochÃĐ) permettent d'accÃĐder à partir de plusieurs ÃĐtats à un seul ÃĐtat (TÃĐlÃĐphone libre). La reprÃĐsentation peut Être ainsi simplifiÃĐe.
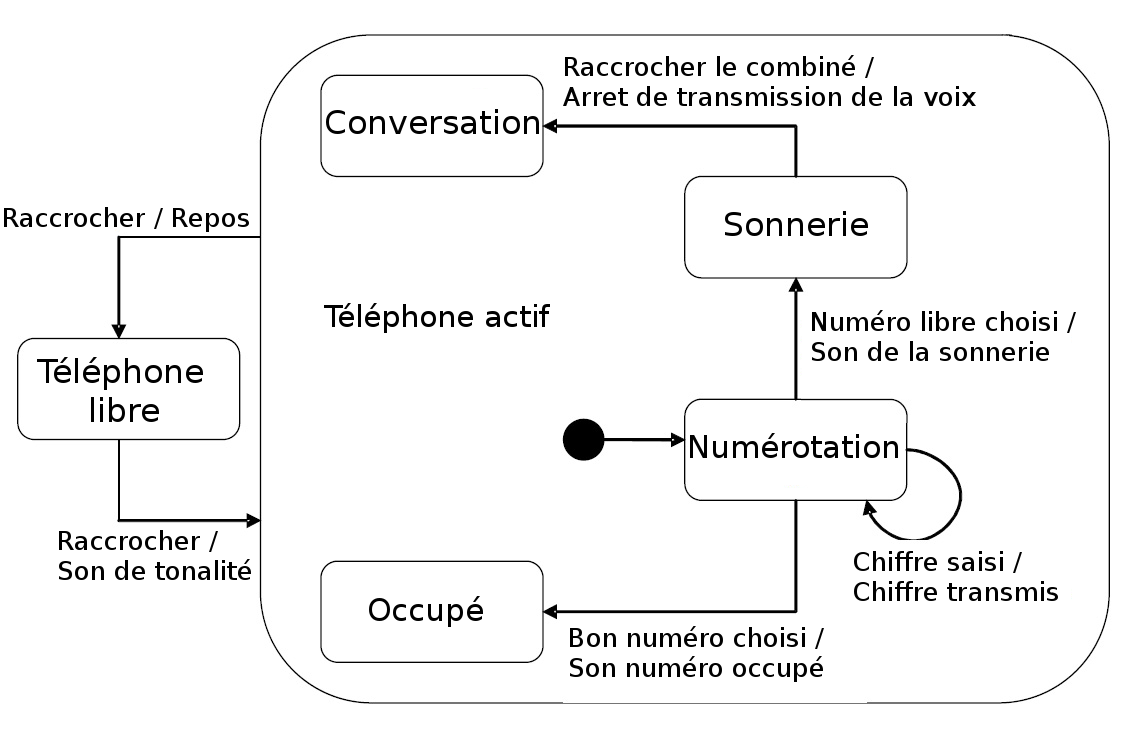
III-D-3. ImplÃĐmentation de diagrammes d'ÃĐtat▲
Il existe plusieurs approches pour implÃĐmenter les diagrammes d'ÃĐtat. Deux d'entre elles sont briÃĻvement abordÃĐs dans ce chapitre. Si vous dÃĐfinissez un projet en C++, vous avez la possibilitÃĐ d'utiliser les modÃĻles de conception d'ÃĐtat (anglais : State Design Pattern). Ces derniers ne sont pas abordÃĐs dans ce cours.
III-D-3-a. Instructions switch emboÃŪtÃĐes▲
Une bonne approche et couramment utilisÃĐe pour programmer les machines d'ÃĐtat est l'imbrication de deux structures switch. La structure externe permet de gÃĐrer les ÃĐtats possibles alors que la structure interne est responsable du traitement des diffÃĐrents ÃĐvÃĐnements. Le code C se prÃĐsente ainsi de la maniÃĻre suivante :
switch(state){
case STATE_1:
switch(event){
case EVENT_1:
action_1();
state = STATE_V;
break;
case EVENT_2:
action_2();
state = STATE_W;
break;
âĶ
}
break;
case STATE_2:
switch(event){
case EVENT_3:
action_3();
state = STATE_X;
break;
case EVENT_4:
action_4();
state = STATE_Y;
break;
âĶ
}
break;
âĶ
}III-D-3-b. Les tableaux▲
Une maniÃĻre ÃĐlÃĐgante consiste à stocker toutes les actions et les ÃĐtats suivants dans un tableau à deux dimensions. Le tableau a la structure suivante :
| E1 | E2 | âĶ | En | E1 âĶ En : ÃvÃĐnement | |
| A1/Sv | âĶ | âĶ | âĶ | S1 | S1 âĶ Sn : Ãtat |
| âĶ | âĶ | âĶ | âĶ | S2 | A1 âĶ An : Action |
| âĶ | âĶ | âĶ | âĶ | âĶ | Sv : Ãtat suivant |
| âĶ | âĶ | âĶ | âĶ | Sn |
Ce tableau contient pour chaque combinaison possible d'ÃĐvÃĐnements et d'ÃĐtats une structure. Cette structure quant à elle contient une information concernant l'action à exÃĐcuter et l'ÃĐtat suivant. Le code C se prÃĐsente en gÃĐnÃĐral comme suit :
// typedef pour State et Event
typedef enum {S1, S2, S3} StateType;
typedef enum {E1, E2, E3, E4, E5, E6, E7, E8, E9} EventType;
/* DÃĐclaration d'un ÃĐlÃĐment du tableau d'ÃĐtats,
qui contient l'action à exÃĐcuter et l'ÃĐtat suivant */
typedef struct tab {
int(*action)(void*);
StateType nextState;
}TabElement;
// DÃĐclaration de toutes les actions
int Action1(void* para);
int Action2(void* para);
int Action3(void* para);
âĶ
// La dÃĐfinition du tableau d'ÃĐtats
TabElement stateTable[3][3] = {
// E1 E2 E3
{ {Action1,S2},{Action2,S2},{Action3,S3} }, // S1
{ {Action4,S1},{Action5,S3},{Action6,S3} }, // S2
{ {Action7,S1},{Action8,S2},{Action9,S3} }, // S3
};
// La dÃĐfinition des actions
int Action1(void* para){
...
return(0);
}
int Action2(void* para){
...
return(0);
}
int Action3(void* para){
...
return(0);
}
...
void main(void){
int para = 0;
// ÃvÃĐnement et ÃĐtat de dÃĐpart
EventType event = E1;
StateType state = S1;
while(1){
// Code à exÃĐcuter à chaque ÃĐvÃĐnement
(*(stateTable[state][event]).action)(¶); // ExÃĐcuter l'action
state = (stateTable[state][event]).nextState; /* Lire le prochain ÃĐtat */
}
}IV. SÃĐcuritÃĐ des systÃĻmes▲
IV-A. Introduction▲
Les exigences de qualitÃĐ pour les systÃĻmes embarquÃĐs sont trÃĻs ÃĐlevÃĐes. Ces exigences concernent le ÂŦ cycle de vie Âŧ complet du produit : depuis la planification en passant par le dÃĐveloppement jusqu'Ã la formation des clients. Voici quelques commentaires concernant la partie matÃĐrielle (hardware) et la partie logicielle (software).
IV-A-1. Hardware▲
La qualitÃĐ de la partie matÃĐrielle (hardware) peut Être dÃĐterminÃĐe statistiquement. Les probabilitÃĐs de dÃĐfaillance (MTTF Mean Time To Fail, ou MTBF, Mean Time Between Failure) des composants sont en gÃĐnÃĐral connues. Cela permet de dÃĐfinir la probabilitÃĐ de dÃĐfaillance du systÃĻme en entier ou le temps nÃĐcessaire pour que celui-ci atteigne un ÃĐtat jugÃĐ comme ÃĐtant dangereux.
La qualitÃĐ de la partie matÃĐrielle peut Être augmentÃĐe grÃĒce à la redondance. La notion de ÂŦ fail-safe mechanism Âŧ est ÃĐgalement utilisÃĐe dans ce genre de systÃĻme. La redondance vise principalement à rÃĐaliser des systÃĻmes (hardware et software) sÃŧrs et fiables. Ces notions sont souvent utilisÃĐes mais elles n'ont pas les mÊmes significations. Les systÃĻmes sÃŧrs sont destinÃĐs à protÃĐger les Hommes. Quant aux systÃĻmes fiables, ils doivent uniquement rÃĐduire leur probabilitÃĐ de dÃĐfaillance afin de rÃĐduire les coÃŧts. Ce qui ne signifie pas nÃĐcessairement plus de sÃĐcuritÃĐ. Les options suivantes peuvent Être envisagÃĐes en fonction des champs d'application :
- surveillance de la partie logicielle à l'aide d'un Watchdog (voir chapitre IV.EWatchdog) ;
- surveillance de la partie matÃĐrielle (horloge et alimentation) par des composants supplÃĐmentaires ;
- surveillance de la partie matÃĐrielle par la partie logicielle (CRC, Test de la RAM, etc.) ;
- partie matÃĐrielle redondante (dÃĐdoublement d'entrÃĐe/sortie, deux processeurs en parallÃĻle ou trois avec une stratÃĐgie de dÃĐcision majoritaire) ;
- partie logicielle redondante (des programmes diffÃĐrents sont exÃĐcutÃĐs sur des processeurs diffÃĐrents).
IV-A-2. Software▲
Le dÃĐveloppement du logiciel peut Être amÃĐliorÃĐ qualitativement par des mesures appropriÃĐes. Contrairement aux logiciels bureautiques, oÃđ les utilisateurs se sont rÃĐsignÃĐs aux problÃĻmes de logiciels (le nom du systÃĻme d'exploitation a ÃĐtÃĐ dÃĐlibÃĐrÃĐment omis ici), la fiabilitÃĐ des logiciels embarquÃĐs doit Être trÃĻs ÃĐlevÃĐe. Ces exigences sont encore plus importantes pour les applications liÃĐes à la sÃĐcuritÃĐ. Le dÃĐveloppement de logiciels de bonne qualitÃĐ n'est possible qu'avec plusieurs mesures :
- des ingÃĐnieurs bien formÃĐs et qualifiÃĐs qui ont une bonne connaissance des piÃĻges courants ;
- rÃĐvision des spÃĐcifications, de la conception et du code ;
- une conception du logiciel de haute qualitÃĐ ;
- code de haute qualitÃĐ grÃĒce à l'utilisation des normes et des directives SW ;
- mÃĐcanismes de dÃĐtection d'erreur dans le logiciel ;
- utilisation des outils d'analyse de code statique ;
- des tests approfondis durant la phase de dÃĐveloppement ;
- tests du systÃĻme complet avant et pendant la mise en service ;
- une documentation complÃĻte, comprÃĐhensible et actualisÃĐe.
IV-B. Le langage de programmation C▲
Un critÃĻre (mais pas le seul) pour la qualitÃĐ des logiciels est le langage de programmation. Le langage C, qui est le plus couramment utilisÃĐ dans les systÃĻmes embarquÃĐs, n'est malheureusement pas sÃŧr au niveau des types et prÃĐsente ÃĐgalement de nombreux autres piÃĻges. Par exemple, les pointeurs en C ont dÃĐjà inquiÃĐtÃĐ de nombreux experts en sÃĐcuritÃĐ (et ÃĐgalement les programmeurs). Toutefois, tout n'est pas perdu, si en tant que programmeur, vous Êtes conscient du problÃĻme. En effet, il faut prendre les prÃĐcautions nÃĐcessaires durant la programmation. Par exemple, il est fortement recommandÃĐ de ne jamais utiliser qu'un sous-ensemble du langage de programmation C. Cette recommandation est valable, non seulement pour des systÃĻmes de sÃĐcuritÃĐ, mais pour tous les programmes d'utilitÃĐ gÃĐnÃĐrale. Une liste exhaustive de telles recommandations est fournie par l'association MISRA-C [MISRA-C]. Certaines d'entre elles sont dÃĐcrites dans la section suivante.
La question qui pourrait Être posÃĐe ici est la suivante : pourquoi faut-il utiliser le langage C pour programmer les systÃĻmes embarquÃĐs, alors que ce dernier est lacunaire. Pour cela, il y a deux raisons importantes :
- PremiÃĻrement, dans domaine de la programmation des microcontrÃīleurs, il n'existe (presque) pas d'alternative. Il faut donc composer avec cela.
- DeuxiÃĻmement, il est plus opportun d'utiliser un langage de programmation que l'on connaÃŪt (en particulier ses faiblesses), pour lequel il existe de bons compilateurs, qu'un langage qui n'est pas rÃĐpandu et pour lequel il n'existe que de mauvais outils de dÃĐveloppement.
IV-B-1. MISRA-C▲
L'association MISRA-C (Motor Industry Software Reliability Association) dÃĐfinit les directives pour l'utilisation du langage de programmation C dans l'industrie automobile, qui prÃĐvalent ÃĐgalement dans d'autres secteurs de l'industrie. Le titre officiel est ÂŦ Guidelines for the use of the C langage in critical systems Âŧ. www.misra.org.uk
MISRA-C 122 dÃĐfinit les rÃĻgles ÂŦ nÃĐcessaires Âŧ et 20 rÃĻgles ÂŦ consultatives Âŧ. La figure ci-dessous illustre deux de ces rÃĻgles. Toutes les rÃĻgles doivent Être respectÃĐes pour pouvoir Être conformes aux directives MISRA.

IV-B-2. Analyse de code statique▲
Les compilateurs C sont en gÃĐnÃĐral trÃĻs tolÃĐrants (ou conviviaux) durant la compilation. Ils ÂŦ ferment plusieurs fois les yeux Âŧ pour que le code puisse Être compilÃĐ et ainsi s'exÃĐcuter plus rapidement. Mais cela peut s'avÃĐrer fatal durant le fonctionnement ! Ce qui est bien entendu beaucoup moins convivial et trÃĻs fÃĒcheux en termes de qualitÃĐ. Il existe diffÃĐrents outils (vÃĐrificateurs de syntaxe) sur le marchÃĐ, qui permettent d'effectuer des analyses statiques du code afin de fournir des messages d'erreurs, des avertissements ou des informations gÃĐnÃĐrales sur le code.
Une bonne approche consiste à faire contrÃīler votre code à l'aide d'un vÃĐrificateur de syntaxe. Les nombreuses rÃĐclamations fournies par ce dernier vont peut-Être vous ÃĐtonner. Ne soyez toutefois pas frustrÃĐ mais montrez-vous au contraire reconnaissant : en effet la phase de test sera d'autant plus facile. Les analyses du code à l'aide d'un vÃĐrificateur de syntaxe devrait commencer au dÃĐbut - et non à la fin - de la phase de programmation afin d'ÃĐviter un flot trop important d'avertissements.
Il existe plusieurs produits sur le marchÃĐ comme ÂŦ PC-Lint Âŧ de Gimpel. De tels outils permettent ÃĐgalement d'examiner si les rÃĻgles de MISRA-C sont respectÃĐes (pas forcÃĐment toutes les rÃĻgles, mais la plupart qui sont spÃĐcifiÃĐes par le fabricant).
IV-C. Murphy et le langage de programmation C▲
Ce chapitre rÃĐpertorie quelques problÃĻmes typiques, qui peuvent survenir avec le langage de programmation C.
Ces indications ne sont pas exhaustives. Elles illustrent cependant quelques-uns des principaux problÃĻmes de ce langage.
IV-C-1. DÃĐpassement de capacitÃĐ dans les tableaux▲
En C, vous pouvez accÃĐder à un tableau en dehors de ses limites, sans que vous puissiez vous en rendre compte (ou juste avant un crash du systÃĻme). ConsidÃĐrez par exemple le code suivant qui est syntaxiquement correct (c'est-à -dire que le compilateur va probablement le compiler sans avertissement) :
char array[10];
char counter = 0;
âĶ
for (counter = 0; counter <= 10; counter++){
array[counter] = 0;
}Dans le code ci-dessus, vous dÃĐpassez les limites du tableau ÂŦarrayÂŧ lorsque ÂŦ counter = 10 Âŧ. Quelle est la consÃĐquence de cela ? Dans le pire de cas, le relieur (anglais : linker) rÃĐserve de l'espace mÃĐmoire pour la variable counter directement à la suite du tableau array. Dans ce cas l'instruction ÂŦ array[counter] = 0Âŧ efface systÃĐmatiquement le contenu de la variable counter. La boucle for devient ainsi une boucle infinie. à cet ÃĐgard, il se peut que vous ayez de la chance et que vous trouviez cette erreur durant les premiÃĻres phases de test. Dans d'autres cas, l'identification du problÃĻme peut s'avÃĐrer beaucoup plus chÃĻre.
Il existe deux approches pour rÃĐsoudre ce problÃĻme :
- Vous portez une attention particuliÃĻre aux limites du tableau pendant le codage. Vous pouvez ÃĐgalement contrÃīler l'index du tableau avant d'accÃĐder à ce dernier. Vous pouvez ÃĐgalement dÃĐmontrer que vous n'avez pas dÃĐpassÃĐ les limites du tableau à l'aide de tests approfondis. Malheureusement, une certaine incertitude demeure toujours.
- Ajoutez un ÃĐlÃĐment supplÃĐmentaire au tableau, que vous initialiserez avec une valeur spÃĐcifique (par ex. 0x55). Testez à prÃĐsent le systÃĻme et contrÃīlez ensuite si la valeur de ce dernier ÃĐlÃĐment n'a pas ÃĐtÃĐ modifiÃĐe.
IV-C-2. DÃĐpassement de capacitÃĐ dans la pile (anglais : stack)▲
Ce problÃĻme est identique à celui liÃĐ aux dÃĐpassements de capacitÃĐ dans les tableaux. Lorsque vous dÃĐpassez les limites de votre pile (trop d'appels de fonctions imbriquÃĐes ou trop de variables locales), vous risquez d'accÃĐder aux segments de la RAM qui contiennent des variables. Les choses peuvent encore se gÃĒter lorsque le programme est exÃĐcutÃĐ Ã partir d'une RAM. En effet, dans ce cas, vous risquez d'ÃĐcrire par-dessus le code.
Les erreurs qui rÃĐsultent de ce genre de dÃĐpassement vont se manifester à un instant donnÃĐ (en fonction des objets rÃĐÃĐcrits et de l'utilisation de ces derniers). Ce qui rend la recherche de telles erreurs encore plus difficile.
Comment un dÃĐbordement de la pile peut-il Être dÃĐterminÃĐ ?
Initialisez votre pile au dÃĐmarrage du systÃĻme avec des valeurs spÃĐcifiques, par exemple 0x55. AprÃĻs un test exhaustif du systÃĻme, vous pouvez alors dÃĐterminer la part de la pile qui a ÃĐtÃĐ utilisÃĐe par votre programme (la limite se situe à l'endroit oÃđ les valeurs spÃĐcifiques d'initialisation 0x55 ont ÃĐtÃĐ rÃĐÃĐcrites).
Quelles sont les solutions pour rÃĐsoudre ces problÃĻmes ?
- Agrandissement de la taille de la pile. De nombreux environnements de dÃĐveloppement permettent de dÃĐfinir la taille de la pile à l'aide d'options pour le relieur (anglais : linker).
- RÃĐduction de la taille des variables locales dans vos fonctions.
- Ãvitez les appels de fonction rÃĐcursive !
IV-C-3. Pointeur NULL▲
Un pointeur qui n'est pas initialisÃĐ adresse la case mÃĐmoire NULL (oÃđ mÊme quelque part ailleurs). Une allocation de mÃĐmoire pour construire une liste dynamique, qui ÃĐchoue par manque de mÃĐmoire disponible, retourne ÃĐgalement l'adresse NULL. Le premier cas est une erreur de programmation classique. Le deuxiÃĻme cas n'est pas une erreur, mais il peut se produire à n'importe quel instant.
Quelles sont les solutions pour rÃĐsoudre ces problÃĻmes ?
Il faut comparer la valeur de chaque pointeur avec l'adresse NULL avant de l'utiliser ! Cette vÃĐrification peut se rÃĐaliser soit avec : if(pointer != NULL), ou avec : assert(pointer != NULL).
IV-C-4. Les interruptions▲
Un microcontrÃīleur possÃĻde de nombreux vecteurs d'interruption, qui sont rassemblÃĐs dans son tableau des vecteurs d'interruption. Normalement, seule une partie de ces vecteurs est utilisÃĐe par votre programme (Timer, interface sÃĐrie et peut-Être encore deux ou trois ports IRQ) alors que la grande partie restante ne l'est pas. Que se passe-t-il alors quand apparaÃŪt une interruption qui n'a pas ÃĐtÃĐ prÃĐvue et n'est par consÃĐquent pas traitÃĐe (par exemple la division par zÃĐro) ? Dans ce cas, le contrÃīleur va accÃĐder au tableau des vecteurs d'interruptions afin de charger l'instruction correspondant à cette interruption. Ce vecteur peut contenir avec de la chance la valeur zÃĐro. Le programme fait ainsi un saut à l'adresse NULL, ce qui correspond en gÃĐnÃĐral à une rÃĐinitialisation du systÃĻme (anglais : reset). Toutefois ce vecteur peut ÃĐgalement contenir une valeur diffÃĐrente de zÃĐro. Le programme fait dans ce second cas un saut à une adresse inconnue, qui engendrera probablement un crash du systÃĻme.
Quelles sont les solutions pour rÃĐsoudre ce problÃĻme ?
Il faut toujours initialiser tous les vecteurs d'interruption. Si vous n'utilisez pas une interruption donnÃĐe, implÃĐmentez pour cette derniÃĻre une routine de traitement d'interruption (anglais : ISR) par dÃĐfaut. Dans cette routine de service, vous pouvez afficher un message d'erreur ou implÃĐmenter une boucle infinie pour le dÃĐbogage.
IV-C-5. Allocation de mÃĐmoire dynamique▲
La mÃĐmoire est allouÃĐe dynamiquement dans les programmes afin de gÃĐnÃĐrer des listes. Cela marche bien tant que la mÃĐmoire disponible est suffisante. Des problÃĻmes apparaissent inÃĐvitablement lorsque la mÃĐmoire requise n'est plus disponible. En d'autres termes, le programme n'a plus de ressource en mÃĐmoire. Un autre problÃĻme est la fragmentation de la mÃĐmoire qui peut survenir avec l'allocation de la mÃĐmoire dynamique.
Quelles sont les solutions pour rÃĐsoudre ce problÃĻme ?
- Essayez de dÃĐfinir les structures de donnÃĐes autant que possible de façon statique.
- Assurez-vous que la mÃĐmoire, qui a ÃĐtÃĐ allouÃĐe dynamiquement, soit ÃĐgalement de nouveau libÃĐrÃĐe.
Vous devez vous en occuper vous-mÊme en C et en C++.
- Testez le systÃĻme ÃĐgalement en termes de ressources en mÃĐmoire : exÃĐcutez votre programme durant des heures ou des jours et regardez ensuite si l'espace mÃĐmoire disponible reste constant.
IV-C-6. Les conditions de course▲
Les conditions de course (anglais : race condition) signifient les situations de course. Lorsque les conditions de course sont remplies, les rÃĐsultats du programme dÃĐpendent du comportement temporel de ce dernier. Les situations de course surviennent lorsqu'il y a une interaction asynchrone entre la partie matÃĐrielle (hardware) et la partie logicielle (software). C'est le cas par exemple avec les Timers ou les convertisseurs A/D. Dans ces cas, les conditions de course se produisent lorsque les donnÃĐes sont lues systÃĐmatiquement par le logiciel, alors qu'elles ont ÃĐtÃĐ changÃĐes de maniÃĻre asynchrone par le hardware.
Exemple Timer : Le code suivant gÃĐnÃĻre des conditions de course (rÃĐfÃĐrence : [Firmware_Handbook]) :
unsigned int timer_hi;
interrupt timer(){
++timer_hi
}
unsigned long read_timer(void){
unsigned int low, high;
low = read_word(timer_register);
high = timer_hi;
return (((unsigned long)high)<<16 + (unsigned long)low);
}Le code ci-dessus est erronÃĐ. En effet, admettons que l'on commence par lire la valeur du registre ÂŦ timer_register Âŧ. Ce registre contient une information sur la partie fractionnaire du temps qui s'ÃĐcoule.
Supposons qu'ensuite se produit un dÃĐpassement de capacitÃĐ engendrant l'incrÃĐmentation de la variable ÂŦ timer_hi Âŧ. Cette variable contient une information sur la partie entiÃĻre du temps. La combinaison de ces deux variables conduit ainsi à une information erronÃĐe sur le temps.
Le problÃĻme peut Être rÃĐsolu à l'aide d'approches diffÃĐrentes :
- considÃĐration du problÃĻme dans la phase de conception (anglais : design) ;
- dÃĐsactiver systÃĐmatiquement les interruptions durant les accÃĻs au matÃĐriel (anglais : hardware) ;
- utilisation des ÂŦ registres de capture Âŧ (anglais : Capture-Register).
Les conditions de course sont souvent à l'origine d'erreurs logicielles, qui sont trÃĻs difficiles à localiser (exemple du Timer ci-dessus) !
IV-C-7. Code rÃĐentrant▲
Les applications embarquÃĐes sont toujours programmÃĐes à l'aide d'interruptions ou parfois ÃĐgalement avec des systÃĻmes d'exploitation temps rÃĐel. Cela signifie qu'une fonction peut Être interrompue à tout instant par une interruption ou par une autre tÃĒche (anglais : task). Le chaos est assurÃĐ Ã partir du moment oÃđ les diffÃĐrentes parties du programme accÃĻdent sans prÃĐcautions spÃĐcifiques aux mÊmes ressources (interfaces matÃĐrielles, variables globales). Par consÃĐquent, les fonctions doivent Être programmÃĐes afin qu'elles soient rÃĐentrantes. C'est-à -dire que :
- les variables globales ne doivent Être accessibles que de façon exclusive (ÂŦ atomique Âŧ) ;
- il ne faut pas appeler les fonctions non rÃĐentrantes (attention avec les fonctions des librairies standard) ;
- les interfaces matÃĐrielles (anglais : hardware interfaces) ne doivent Être accessibles que de façon exclusive.
La meilleure façon d'obtenir l'accÃĻs exclusif, c'est de dÃĐsactiver les interruptions durant l'accÃĻs. Toutefois, cela implique une augmentation des temps de latence pour le traitement des interruptions. Par consÃĐquent, les accÃĻs doivent Être aussi courts que possibles.
Dans ce contexte la rÃĻgle importante à respecter est la suivante :
ÂŦ Share the code, not the data Âŧ !
IV-C-8. Programmation dÃĐfensive▲
La programmation dÃĐfensive signifie que l'on considÃĻre toutes les ÃĐventualitÃĐs : arguments transmis aux fonctions non plausibles, transmission de donnÃĐes erronÃĐes, sÃĐquences temporelles non prÃĐvues, etc.). Lorsque vous programmez de façon dÃĐfensive, ce qui est particuliÃĻrement recommandÃĐ pour des systÃĻmes oÃđ la sÃĐcuritÃĐ est essentielle, vÃĐrifiez tout auparavant. Cela signifie en particulier que :
- la gamme de valeur des arguments transmis aux fonctions doit Être contrÃīlÃĐe au dÃĐbut de ces derniÃĻres ;
- les transmissions de donnÃĐes doivent Être vÃĐrifiÃĐes systÃĐmatiquement (Check sum) ;
- la plausibilitÃĐ des rÃĐsultats doit Être vÃĐrifiÃĐe.
La programmation dÃĐfensive permet d'augmenter la sÃĐcuritÃĐ du systÃĻme. Cela n'est cependant pas gratuit. En effet cette approche nÃĐcessite plus de code et, par consÃĐquent, plus de puissance de calcul, plus de capacitÃĐ de stockage et plus de dÃĐveloppement.
IV-C-9. assert()▲
assert() est une macro de la bibliothÃĻque standard. assert() permet d'ÃĐvaluer de façon trÃĻs simple et efficace diverses conditions durant l'exÃĐcution du programme :
assert(expression);Lorsque la condition ÃĐvaluÃĐe se rÃĐvÃĻle Être fausse (valeur nulle), la macro assert() livre un message d'erreur à travers le canal stderr. Ce message a typiquement la forme suivante :
Assertion failed: expression, file filename, line nnnLa macro assert() sera ignorÃĐe lorsque la macro NDEBUG est dÃĐfinie avant l'inclusion de la bibliothÃĻque standard <assert.h>.
Les exemples d'application de la macro assert() sont les tests de pointeur (pointeur non nul) ou de gamme de valeurs pour les paramÃĻtres, etc.
IV-C-10. Optimisation du code C▲
Les compilateurs C essayent de gÃĐnÃĐrer un code objet le plus optimisÃĐ possible. Cela signifie que ce dernier doit Être à la fois aussi rapide et compact que possible. Le rÃĐsultat du compilateur peut ÃĐgalement Être influencÃĐ de façon significative par la maniÃĻre dont le code C est dÃĐfini :
- Essayez d'ÃĐviter autant que possible les variables globales. DÃĐfinissez plutÃīt les variables locales à l'intÃĐrieur des fonctions. Le compilateur peut ainsi stocker ces derniÃĻres dans des registres locaux - plutÃīt que de les placer dans la mÃĐmoire externe (RAM), ce qui diminue le temps d'accÃĻs aux variables. Essayez ÃĐgalement de rÃĐduire autant que possible le nombre de variables locales. En effet, le nombre de registres est limitÃĐ et les variables, qui ne peuvent pas Être stockÃĐes dans des registres, sont placÃĐes sur les piles. Cependant, si vous avez toujours besoin de nombreuses variables locales, essayez d'utiliser ces derniÃĻres de façon limitÃĐe à l'intÃĐrieur de la fonction. Ainsi, le compilateur peut attribuer un seul registre aux diverses variables durant l'exÃĐcution de la fonction.
- Ãvitez les opÃĐrations de prises d'adresse avec les variables locales. En effet, cela empÊche le compilateur de les stocker dans des registres.
- L'assembleur en ligne ne devrait Être utilisÃĐ qu'en dernier recours. En effet, le compilateur n'a pas le droit d'optimiser le code C autour de ces derniers. Utilisez plutÃīt les sous-routines en assembleur.
- Ãvitez de dÃĐfinir des fonctions avec des listes de paramÃĻtres variables (comme printf). En effet, l'appel de ces fonctions nÃĐcessite en gÃĐnÃĐral plus de ressources systÃĻmes.
- Remplacez les fonctions trÃĻs courtes (1 à 3 lignes de code) par des macros ou des fonctions en ligne. Les ressources systÃĻmes nÃĐcessaires à l'appel des fonctions peuvent ainsi Être rÃĐduites au maximum. En effet, le compilateur copie littÃĐralement les lignes de code des fonctions en ligne aux endroits appropriÃĐs dans le programme. Ce qui d'une part augmente considÃĐrablement la vitesse d'exÃĐcution du programme et d'autre part - surtout avec les fonctions trÃĻs courtes - rÃĐduit le nombre d'instructions assembleur.
- La transmission des arguments aux fonctions devrait Être rÃĐalisÃĐe à l'aide de paramÃĻtres au lieu de variables globales. En effet, dans le premier cas, le compilateur utilise les registres pour transmettre les arguments. Cette procÃĐdure est beaucoup plus rapide que l'accÃĻs systÃĐmatique aux variables globales, qui sont stockÃĐes dans la mÃĐmoire externe (RAM). Les premiers arguments sont en gÃĐnÃĐral transmis avec des registres et les suivants avec la pile (anglais : stack). Par consÃĐquent, il faut faire ÃĐgalement attention au nombre d'arguments qui vont Être transmis à la fonction.
- Si vous souhaitez transmettre des structures de donnÃĐes comme paramÃĻtre à des fonctions, transmettez ces derniÃĻres avec des pointeurs constants (avec le mot clÃĐ ÂŦconstÂŧ). Le compilateur dÃĐposerait autrement la structure entiÃĻrement sur la pile.
- Utilisez le mot-clÃĐ ÂŦvolatileÂŧ pour indiquer au compilateur que la variable ne peut pas Être stockÃĐe dans un registre. Cette derniÃĻre sera ainsi toujours dÃĐposÃĐe dans la mÃĐmoire externe (RAM). Cette dÃĐfinition est mÊme indispensable pour les variables qui permettent d'accÃĐder à la partie matÃĐrielle (anglais : hardware) comme le ÂŦ Timer Âŧ.
- Essayez les diffÃĐrents niveaux d'optimisation du compilateur. Le niveau le plus haut ne gÃĐnÃĻre ici pas forcÃĐment le code le plus rapide ou le plus compact.
- Utilisez toujours, pour la dÃĐfinition des variables, le type de donnÃĐes le plus adÃĐquat en fonction de la taille de la CPU (8, 16 ou 32 bits). Autrement, le compilateur doit effectuer une, voire plusieurs opÃĐrations cast. Les opÃĐrations arithmÃĐtiques avec le type char sont en principe trÃĻs efficaces sur les microcontrÃīleurs 8 bits. Avec ces derniers, les opÃĐrations 16 ou 32 bits nÃĐcessitent des fonctions de la bibliothÃĻque standard, ce qui n'est pas efficace. Un microcontrÃīleur 8 bits est en gÃĐnÃĐral dÃĐpassÃĐ avec les calculs à virgule flottante. Les fonctions de la bibliothÃĻque standard sont alors trÃĻs complexes et leur temps d'exÃĐcution trÃĻs long.
- Les microcontrÃīleurs 32 bits possÃĻdent souvent des contraintes d'alignement pour les adresses des variables. Essayez de dÃĐclarer systÃĐmatiquement les membres 32 bits en premier, les membres 16 bits en second et les membres 8 bits à la fin dans les structures de donnÃĐes. Cela empÊche le compilateur de devoir insÃĐrer des espaces libres (ÂŦ padding Âŧ) entre les diffÃĐrents types de membres, ce qui a tendance à augmenter la taille de la structure de donnÃĐes.
- Ne dÃĐfinissez pas de code ÂŦ intelligent Âŧ, qui n'est pas comprÃĐhensible pour votre collÃĻgue (et pour vous aprÃĻs quelques jours). Le compilateur ne comprend pas ce code et ne peut donc l'optimiser. DÃĐfinissez votre code plutÃīt de façon ÂŦ simple et continue Âŧ. ÂŦ Write simple and understandable code Âŧ !
- DÃĐfinissez une structure ÂŦ switch Âŧ au lieu d'un tableau de saut (anglais : Jump-Table). En effet, le compilateur va gÃĐnÃĐrer un tableau de saut optimal pour le microcontrÃīleur sÃĐlectionnÃĐ pour cette instruction. Le code reste ainsi parfaitement portable.
IV-D. SÃĐcuritÃĐ au niveau du systÃĻme▲
Les parties matÃĐrielles et logicielles ne sont pas uniquement critiques pour la sÃĐcuritÃĐ du systÃĻme. En effet, cette derniÃĻre dÃĐpend du cycle de vie complet du produit, depuis sa spÃĐcification jusqu'Ã la formation des clients.
Les paragraphes suivants traitent quelques points qui concernent surtout la phase de dÃĐveloppement.
IV-D-1. La conception▲
Comment les amÃĐliorations peuvent-elles Être intÃĐgrÃĐes sans problÃĻmes ? La structure finale d'un programme dÃĐpend de plusieurs critÃĻres. Le critÃĻre le plus important est celui de la mise en Åuvre des spÃĐcifications. Toutefois, la conception peut ÃĐgalement Être influencÃĐe par le programmeur lui-mÊme. Les expÃĐriences et les compÃĐtences de ce dernier jouent ici un rÃīle majeur. C'est un peu la discipline reine de l'ingÃĐnieur logiciel, la suite n'est plus que du codage et des tests. Les erreurs de conception sont en gÃĐnÃĐral trÃĻs problÃĐmatiques. La correction de ces derniÃĻres nÃĐcessite souvent beaucoup d'efforts. En effet, une grande partie du code doit Être modifiÃĐe et les tests doivent Être effectuÃĐs à nouveau.
La conception a un impact majeur sur la qualitÃĐ du code. Cette phase doit inclure les ÃĐlÃĐments suivants :
- la modularisation de votre systÃĻme en fichiers / classes / tÃĒches ;
- la description des interfaces de ces modules ;
- la communication entre ces modules ;
- le comportement temporel des diffÃĐrents modules et de l'ensemble du systÃĻme ;
- les interfaces au processus technique et à l'utilisateur.
IV-D-2. SpÃĐcification et exÃĐcution des tests▲
Les tests ne devraient pas Être simplement rÃĐalisÃĐs à la fin du projet avec la devise : dÃĐmarrer le systÃĻme - ce dernier fonctionne - donc tout est bon. Les tests doivent plutÃīt Être spÃĐcifiÃĐs durant la conception du systÃĻme.
Cette spÃĐcification doit contenir les types, les procÃĐdures et les paramÃĻtres des tests. Elle peut Être obtenue à partir des spÃĐcifications du systÃĻme. La rÃĐdaction des spÃĐcifications de test devrait Être rÃĐalisÃĐe de prÃĐfÃĐrence durant la phase de conception du systÃĻme ou, dans tous les cas, avant la phase de codage.
Des tests sont particuliÃĻrement importants pour les systÃĻmes embarquÃĐs. Les erreurs, qui ne sont pas trouvÃĐes durant la phase des tests, sont trÃĻs coÃŧteuses, voire dangereuses. Dans ce cas, vous devez rappeler les systÃĻmes vendus (en effet, vous ne pouvez pas envoyer simplement une mise à jour du logiciel) ou installer une nouvelle version du logiciel chez le client. La rÃĻgle d'or stipule que si vous avez programmÃĐ durant un mois, vous devriez ÃĐgalement tester durant un mois !
Les tests sont toujours rÃĐalisÃĐs sur plusieurs niveaux : ils sont effectuÃĐs individuellement sur les fonctions au niveau des modules ; puis sur les diffÃĐrentes parties du systÃĻme et finalement sur le systÃĻme dans son ensemble dans un environnement rÃĐel. Les ingÃĐnieurs logiciels sont en gÃĐnÃĐral beaucoup trop indulgents face à leur propre code. Mais ces derniers souhaitent-ils vraiment que quelqu'un d'autre trouve les erreurs à leur place ? Les grandes entreprises emploient des ingÃĐnieurs de test : ces derniers se rÃĐjouissent toujours lorsqu'ils trouvent de nouvelles erreurs. Mais, il est en gÃĐnÃĐral beaucoup plus agrÃĐable de trouver ses erreurs soi-mÊme.
Par consÃĐquent : essayez de vraiment torturer votre logiciel et d'aller à ses limites. Ici vous serez certainement beaucoup plus crÃĐatif ou plutÃīt plus destructif qu'une personne tierce.
Des nombreux ouvrages ont ÃĐtÃĐ publiÃĐs sur les modÃĻles et les procÃĐdures de tests. Voici quelques points clÃĐs en bref :
- VÃĐrifier en particulier les interfaces pour les utilisateurs et pour le processus technique (les capteurs, les convertisseurs, les interfaces utilisateur d'entrÃĐe et de sortie, etc.). Vous ne pouvez sÃŧrement pas tester toutes les combinaisons possibles d'interfaces utilisateur. Mais quelques types de clavier devraient par exemple Être possibles.
- VÃĐrifier en profondeur les interfaces de communication. Si vous avez par exemple une interface sÃĐrielle, alors bombardez votre systÃĻme avec des demandes, envoyez-lui ÃĐgalement des protocoles non dÃĐfinis, etc.
- VÃĐrifier le comportement de votre systÃĻme mÊme en cas de surcharge.
Une bonne approche consiste à travailler avec deux versions du code : une version pour un fonctionnement standard et une version pour le dÃĐbogage. Cette derniÃĻre contient du code supplÃĐmentaire pour exÃĐcuter les tests. Cela peut Être dÃĐfini en C avec une macro de la maniÃĻre suivante :
#define _DEBUG
...
statement;
...
#ifdef _DEBUG
// additional testing and error messages output
#endifVous pouvez commuter entre les versions en commentant l'instruction ÂŦ #define_DEBUG Âŧ. Le code pour les deux versions est ainsi dÃĐfini dans les mÊmes fichiers.
Il existe de nombreuses normes et directives pour effectuer des tests logiciels, dont les plus recommandÃĐes sont les suivantes :
- IEEE 829, Standard for Software Test Documentation ;
- IEEE 1008, Standard for Software Unit Testing ;
- IEEE 1012, Standard for Software Verification and Validation.
IV-D-3. La documentation▲
Une bonne documentation permet de s'assurer que :
- les changements ou les amÃĐliorations peuvent Être effectuÃĐs sans erreurs ;
- toutes les erreurs peuvent Être localisÃĐes plus facilement ;
- vos collÃĻgues peuvent Être intÃĐgrÃĐs dans le dÃĐveloppement logiciel, sans que ces derniers ne vous posent continuellement des questions (et sans que ces derniers ne vous dÃĐrangent) ;
- les tests peuvent Être rÃĐpÃĐtÃĐs ou complÃĐtÃĐs.
La documentation est votre carte de visite. Si, par manque de temps ou de ressources, vous renoncez à dÃĐfinir une documentation, vous le regretterez plus tard (par exemple, lorsque vous devez remettre à jour votre code).
Si, par manque de temps ou de ressources, vos supÃĐrieurs exigent une documentation rÃĐduite, alors dÃĐfendez-vous dans votre propre intÃĐrÊt.
Une bonne documentation constitue un autre avantage à ne pas sous-estimer. Si une erreur de votre logiciel a causÃĐ des dommages à des biens ou des personnes, vous vous trouverez en tant que dÃĐveloppeur sans bonne documentation en manque de preuve. Aujourd'hui, les erreurs logicielles ne peuvent pas Être exclues. Mais une bonne conception, un bon rapport et des tests bien documentÃĐs peuvent prouver que vous avez fait tout votre possible pour ÃĐviter les erreurs.
La forme de la documentation est secondaire. L'important est que tout y est dÃĐcrit. Cela commence par la conception, en incluant les diffÃĐrentes variantes et leur ÃĐvaluation. Cette derniÃĻre est suivie par la description du code sans oublier la description comprÃĐhensible des tests.
IV-D-4. Reviews▲
Effectuez rÃĐguliÃĻrement des rÃĐexamens (reviews) durant le dÃĐveloppement du projet. Cela s'applique aux spÃĐcifications (en incluant ÃĐgalement les spÃĐcifications de test), la conception et le code.
Les rÃĐexamens du code ne sont pas effectuÃĐs dans de nombreuses entreprises ÂŦ par manque de temps Âŧ. C'est trÃĻs dommage. En effet, le temps investi dans les rÃĐexamens est gagnÃĐ par la suite durant le dÃĐbogage. Certaines erreurs typiques, telles que les conditions de course, ne peuvent Être isolÃĐes par les dÃĐveloppeurs expÃĐrimentÃĐs que durant les phases de rÃĐexamens. Un autre avantage des rÃĐexamens est l'ÃĐchange de connaissances entre les dÃĐveloppeurs.
IV-E. Watchdog▲
IV-E-1. Introduction▲
La tÃĒche du Watchdog (français : horloge de surveillance) est de rÃĐinitialiser un microcontrÃīleur (c'est-à -dire de ramener le systÃĻme à un ÃĐtat dÃĐfini) à partir d'un ÃĐtat indÃĐfini. Cet ÃĐtat est souvent le rÃĐsultat d'un comportement erronÃĐ du programme, par exemple une boucle infinie. Dans le langage courant, on appelle cela un plantage informatique (anglais : system crash).
L'utilisation d'un watchdog est fortement recommandÃĐe pour tous les systÃĻmes (mÊme avec des applications trÃĻs simples). Par consÃĐquent, de nombreux microcontrÃīleurs contiennent un watchdog interne.
IV-E-2. Le watchdog externe▲
Les watchdogs externes peuvent exÃĐcuter - en complÃĐment des applications de surveillance du processeur - les tÃĒches suivantes :
- Surveillance de l'alimentation du systÃĻme.
- Surveillance de l'horloge du systÃĻme.
Les courtes interruptions d'alimentation sont en gÃĐnÃĐral trÃĻs dangereuses pour les systÃĻmes à microprocesseur.
En effet, ces derniÃĻres peuvent faire entrer le processeur dans des ÃĐtats non dÃĐfinis. Les watchdogs externes surveillent ÃĐgalement l'alimentation et gÃĐnÃĻrent un reset en cas de problÃĻme. Cette fonctionnalitÃĐ peut ÃĐgalement Être reprise par le module reset.
Les watchdogs externes possÃĻdent en gÃĐnÃĐral leur propre base de temps. Ce qui leur permet de surveiller ÃĐgalement l'horloge du systÃĻme.
Le circuit de watchdog externe est rÃĐalisÃĐ typiquement de la maniÃĻre suivante :
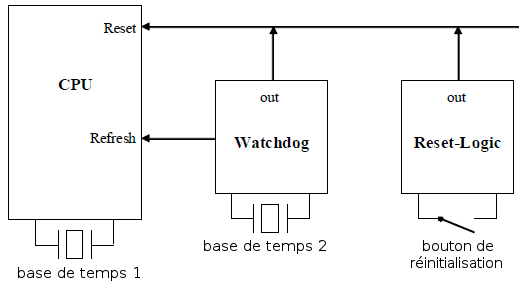
IV-E-3. Le watchdog interne▲
Un watchdog interne (c'est-à -dire intÃĐgrÃĐ dans un microcontrÃīleur) gÃĐnÃĻre ÃĐgalement un reset en cas d'erreur. Un tel reset ne se distingue en gÃĐnÃĐral pas de celui qui est gÃĐnÃĐrÃĐ de façon externe.
Selon la famille des microcontrÃīleurs, il existe des watchdogs internes qui possÃĻdent leur propre base de temps.
Cette derniÃĻre est en gÃĐnÃĐral produite à l'aide d'un circuit RC.
IV-E-4. Fonctionnement du watchdog▲
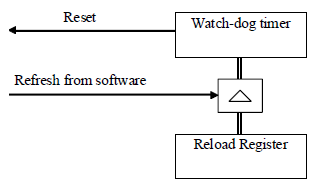
Le cÅur du watchdog est un registre compteur, qui est remis à zÃĐro pÃĐriodiquement par le logiciel. Un dysfonctionnement dans cette procÃĐdure de rafraÃŪchissement engendre un dÃĐpassement de capacitÃĐ du compteur et dÃĐclenche une rÃĐinitialisation du systÃĻme.
La figure suivante illustre la structure de base d'un watchdog :
IV-E-5. DÃĐmarrage du watchdog▲
Le dÃĐmarrage du watchdog s'effectue de deux maniÃĻres :
- De façon hardware aprÃĻs le reset. Cela prÃĐsente l'avantage que le processus de contrÃīle du microcontrÃīleur dÃĐbute à son dÃĐmarrage.
- De façon software en fixant la valeur des bits de contrÃīle appropriÃĐs. Cela devrait Être rÃĐalisÃĐ le plus tÃīt possible dans le code (c'est-à -dire avant l'initialisation du systÃĻme).
IV-E-6. RafraÃŪchissement du watchdog▲
Le rafraÃŪchissement du watchdog s'effectue ÃĐgalement de façon logicielle en fixant la valeur des indicateurs (anglais : flag) appropriÃĐs. Dans ce contexte, il est trÃĻs important que les opÃĐrations de rafraÃŪchissement ne soient pas ÃĐparpillÃĐes au hasard dans le code. En effet, il est plutÃīt recommandÃĐ d'effectuer ces opÃĐrations une seule fois par cycle d'exÃĐcution du programme, par exemple à la fin de la boucle principale main().
La procÃĐdure de rafraÃŪchissement peut Être combinÃĐe avec des clÃĐs afin d'augmenter encore plus la sÃĐcuritÃĐ du systÃĻme. La combinaison des clÃĐs avec un watchdog permet de rÃĐaliser les fonctionnalitÃĐs suivantes :
- contrÃīler le comportement temporel d'un programme ;
- vÃĐrifier si les fonctions les plus importantes ont effectivement ÃĐtÃĐ exÃĐcutÃĐes.
La procÃĐdure est la suivante : une ou plusieurs clÃĐs sont nÃĐcessaires. Les clÃĐs sont des variables communes, qui permettent de contrÃīler le dÃĐroulement du programme. Une valeur spÃĐcifique est attribuÃĐe à une clÃĐ dans toutes les fonctions importantes du systÃĻme. Si votre programme comporte de nombreux points à contrÃīler, vous pouvez ÃĐgalement utiliser une seule variable clÃĐ. Dans ce cas, vous pouvez systÃĐmatiquement changer la valeur de votre clÃĐ Ã l'aide d'un polynÃīme de CRC. à la fin d'un cycle d'exÃĐcution du programme, la valeur de la clÃĐ vous assurera systÃĐmatiquement que toutes les fonctions importantes ont ÃĐtÃĐ appelÃĐes dans un ordre adÃĐquat. En effet, si cette derniÃĻre est correcte, vous pouvez effacer son contenu et rafraÃŪchir le watchdog. Toutefois, si la clÃĐ est erronÃĐe, cela signifie que le programme s'est comportÃĐ de façon erronÃĐe. Dans ce cas, le watchdog ne doit pas Être rafraÃŪchi afin d'engendrer le redÃĐmarrage du systÃĻme avec un reset.
V. Connexion de la pÃĐriphÃĐrie▲
Ce chapitre traite la connexion du microcontrÃīleur aux composants pÃĐriphÃĐriques, tels que les capteurs, actionneurs et ÃĐlÃĐments de commande.
V-A. Bus d'adresse / de donnÃĐes▲
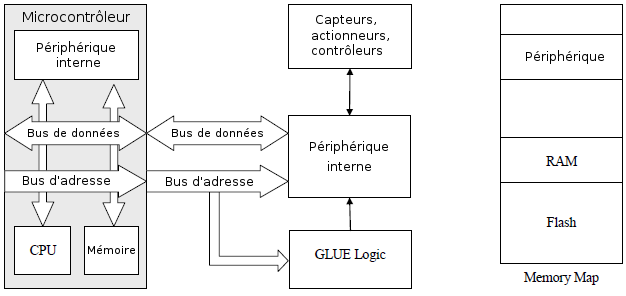
C'est la maniÃĻre la plus simple d'ajouter des composants pÃĐriphÃĐriques qui ne sont pas disponibles dans le microcontrÃīleur. Des fonctionnalitÃĐs supplÃĐmentaires peuvent ainsi Être ajoutÃĐes aux systÃĻmes embarquÃĐs comme : les convertisseurs A/D, les contrÃīleurs USB ou CAN. La communication entre le microcontrÃīleur et les composants pÃĐriphÃĐriques s'effectue alors avec les bus d'adresse et de donnÃĐes. Par consÃĐquent, il leur faut ÃĐgalement attribuer des plages d'adresse dans le plan de mÃĐmoire.
V-B. Port d'entrÃĐe et de sortie numÃĐrique▲
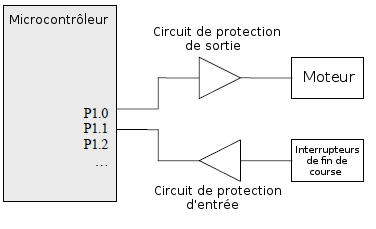
Beaucoup de microcontrÃīleurs proposent des ports d'entrÃĐe et de sortie numÃĐriques (GPIO : General Purpose Input/Output). Ces derniers sont en gÃĐnÃĐral des entrÃĐes ou des sorties multifonctionnelles et sont parfois regroupÃĐs par groupe de huit ports (1 octet).
Ces ports permettent de lire directement les signaux numÃĐriques à leur entrÃĐe ou de piloter des ÃĐtages d'amplification de sortie.
Lorsque des composants externes doivent Être pilotÃĐs à l'aide des ports GPIO, il faut vÃĐrifier dans la fiche technique du microcontrÃīleur que ces derniers sont capables de fournir le courant nÃĐcessaire. En effet, le courant fourni par ces ports ne se limite en gÃĐnÃĐral qu'à quelques mA. Par consÃĐquent, dans certains cas il faut ajouter un ÃĐtage d'amplification externe.
Les ports doivent toujours Être complÃĐtÃĐs de circuits de protection d'entrÃĐe et de sortie afin d'optimiser au mieux leur compatibilitÃĐ ÃĐlectromagnÃĐtique (CEM).
L'accÃĻs aux ports est relativement simple en C :
- Les diffÃĐrents pins d'un port peuvent Être mis à 1 ou à 0 de façon individuelle avec des opÃĐrations logiques binaires ET ou OU. Par exemple : P1 |= 0x01; met le pin P1.0 à 1. Remarque : cette opÃĐration lit d'abord l'ÃĐtat actuel du port P1 avant de mettre le pin P1.0 à 1.
- Certains microcontrÃīleurs permettent de programmer les pins des ports bit par bit. Ce genre d'opÃĐrations peut Être rÃĐalisÃĐ soit à l'aide d'instructions en Assembleur (ces instructions sont alors ÃĐgalement soutenues par les compilateurs C : P1_0 = 1; met par exemple le pin P1.0 à 1) ou elles sont soutenues directement par le hardware (ex. bit-banding avec ARM).
V-C. RS232▲
L'interface RS232 est trÃĻs rÃĐpandue dans le domaine embarquÃĐ. Cette interface permet par exemple de gÃĐrer des affichages LCD ou des lignes de commande (Command Line Interface). La plupart des microcontrÃīleurs possÃĻdent dÃĐjà une interface RS232. Toutefois, les tensions de sortie de ces derniÃĻres correspondent au niveau TTL. Par consÃĐquent, un convertisseur de tension externe doit Être ajoutÃĐ au systÃĻme.
Les interfaces RS232 sont accessibles à l'aide de registres.
- Les tampons de transmission et de rÃĐception contiennent systÃĐmatiquement 1 octet. Les deux tampons possÃĻdent souvent la mÊme adresse, car il n'est possible d'ÃĐcrire que dans le tampon de transmission et de lire qu'à partir du tampon de rÃĐception.
- Les registres de contrÃīle, qui permettent de dÃĐfinir les modes de fonctionnement (la frÃĐquence de transmission (baud rate), le format des donnÃĐes, le bit de paritÃĐ, etc.) et les interruptions.
Les interfaces RS232 soutiennent diffÃĐrents modes de fonctionnement. Par exemple, ils peuvent fonctionner soit en mode synchrone ou en mode asynchrone. La frÃĐquence de transmission est souvent dÃĐfinie avec un Timer standard. Certaines interfaces RS232 possÃĻdent toutefois leur propre gÃĐnÃĐrateur de frÃĐquence. Le Timer peut ainsi Être utilisÃĐ pour d'autres applications.
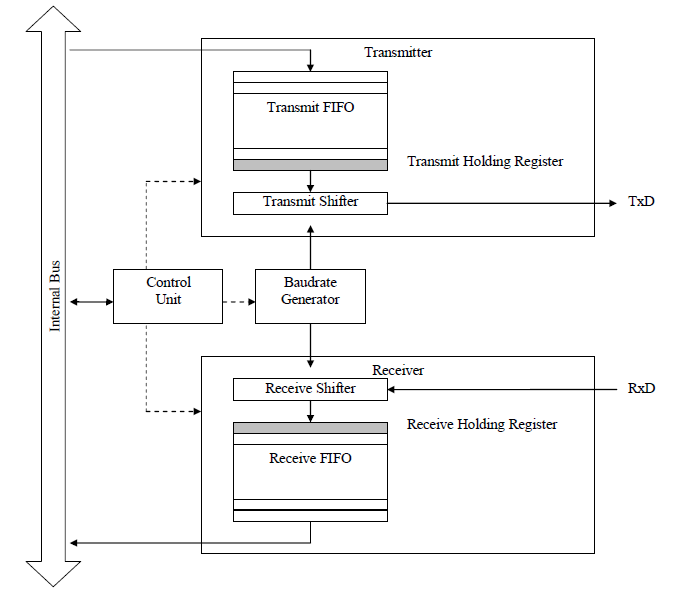
Le schÃĐma bloc de l'interface RS232 est typiquement le suivant :
V-D. SPI▲
L'interface SPI (Serial Peripheral Interface) est un bus sÃĐriel à haut dÃĐbit, destinÃĐ Ã la communication entre le microcontrÃīleur et la pÃĐriphÃĐrie. Ce dernier est souvent utilisÃĐ pour la communication avec des extensions d'entrÃĐe et de sortie, des affichages LCD ainsi que des convertisseurs A/D et D/A. Il peut ÃĐgalement Être utilisÃĐ pour la communication entre microcontrÃīleurs.
La figure suivante illustre le principe de fonctionnement du SPI :
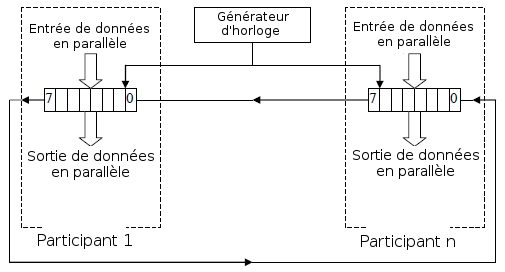
L'interface SPI est toujours utilisÃĐe en mode maÃŪtre-esclave. Le maÃŪtre est alors responsable de la gÃĐnÃĐration de la frÃĐquence d'horloge. Le SPI peut travailler de façon duplex à l'aide de deux lignes de transmission : MOSI (Master Out Slave In) et MISO (Master In Slave Out). Les esclaves peuvent Être connectÃĐs soit de façon parallÃĻle (c'est-à -dire que toutes les sorties des esclaves sont rassemblÃĐes et connectÃĐes à l'entrÃĐ MISO du maÃŪtre) ou de façon sÃĐrielle (la sortie d'un esclave est connectÃĐe à l'entrÃĐe du prochain esclave et la sortie du dernier esclave est connectÃĐe à l'entrÃĐe MISO du maÃŪtre).
Le microcontrÃīleur ÃĐcrit les donnÃĐes à transmettre dans un tampon de transmission. Ces derniÃĻres sont sÃĐrialisÃĐes à l'aide d'un registre à dÃĐcalage (comme une transmission RS232). Les donnÃĐes reçues sont ÃĐgalement converties à l'aide d'un registre à dÃĐcalage. Le microcontrÃīleur peut alors lire ces donnÃĐes de façon parallÃĻle dans le tampon de rÃĐception. Du fait que les interfaces SPI ont une bande passante relativement ÃĐlevÃĐe, les tampons de transmission et de rÃĐception contiennent souvent plusieurs octets.
V-E. I2C▲
V-E-1. Aperçu▲
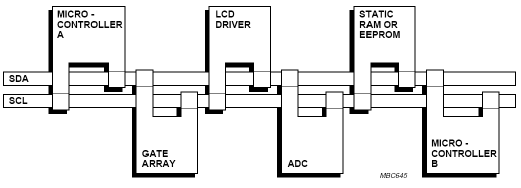
Le bus I2C (Inter Integrated Circuit) a ÃĐtÃĐ dÃĐveloppÃĐ par l'entreprise Philips. Ce bus est utilisÃĐ pour connecter les composants pÃĐriphÃĐriques comme l'EEPROM, les affichages LCD ou RTC (Real Time Clock) au microcontrÃīleur.
Le bus I2C est composÃĐ de deux fils, ce qui rÃĐduit la partie hardware de façon drastique. Ce bus comprend une ligne d'horloge SCL (Serial Clock) et une ligne de donnÃĐes SDA (Serial Data). La communication est par consÃĐquent synchrone. Son mode d'utilisation est souvent du type maÃŪtre et esclave. Cependant, il soutient ÃĐgalement le mode multimaÃŪtre.
La figure suivante illustre une application typique avec le bus I2C :
Source : Philips, The I2C-Bus Specification, V2.1, Jan 2000
V-E-2. Protocole▲
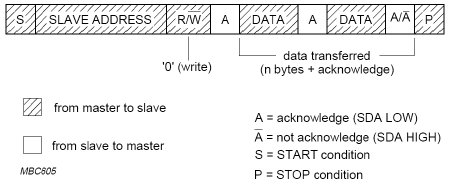
Le protocole du bus est dÃĐfini de la maniÃĻre suivante :
Source : Philips, The I2C-Bus Specification, V2.1, Jan 2000
Le transfert de donnÃĐes entre le maÃŪtre et l'esclave s'effectue de la maniÃĻre suivante :
- Le maÃŪtre dÃĐmarre le transfert des donnÃĐes en envoyant le bit de dÃĐmarrage. Tous les esclaves entrent ainsi dans un ÃĐtat passif d'ÃĐcoute.
- Le maÃŪtre envoie ensuite l'adresse de l'esclave avec lequel il aimerait communiquer. Cette adresse est composÃĐe de 7 bits.
- Le maÃŪtre envoie le bit R/W, qui fixe le sens de la communication : ÃĐcriture depuis le maÃŪtre à l'esclave ou lecture depuis l'esclave au maÃŪtre.
- Le protocole I2C exige des confirmations (acknowledge) aprÃĻs chaque transmission d'un octet. L'esclave accrÃĐdite avec le premier bit de confirmation qu'il est prÊt pour la communication.
- Le transfert de donnÃĐes a lieu entre le maÃŪtre et l'esclave. Un bit de confirmation est ÃĐgalement ÃĐchangÃĐ ici aprÃĻs chaque transmission d'un octet. Ce bit est fourni par le maÃŪtre dans le mode lecture et par l'esclave dans le mode ÃĐcriture.
- Le transfert se termine avec un bit d'arrÊt.
Le nombre d'octets à transmettre et le sens de la transmission varie en fonction des composants pÃĐriphÃĐriques.
Ces informations sont fournies en gÃĐnÃĐral par la documentation de ces derniers. Le maÃŪtre n'ÃĐcrit par exemple qu'un octet dans un convertisseur D/A. Alors qu'avec une EEPROM, qui possÃĻde un espace d'adressage interne, le maÃŪtre doit d'abord envoyer avec le champ ÂŦ Offset Âŧ l'adresse de la case mÃĐmoire à accÃĐder. Le transfert de donnÃĐes n'est effectuÃĐ qu'ensuite jusqu'au bit ArrÊt.
Le tableau suivant contient quelques exemples de transmissions (le bit de confirmation n'y est pas affichÃĐ) :
| Composant | Protocole | |||||||||
| Convertisseur D/A | DÃĐmarrage | Adresse de l'esclave | Wr | DonnÃĐes | ArrÊt | |||||
| Ecriture RAM | DÃĐmarrage | Adresse de l'esclave | Wr | DonnÃĐes | DonnÃĐes | |||||
| Lecture RAM | DÃĐmarrage | Adresse de l'esclave | Wr | DonnÃĐes | ArrÊt | DÃĐmarrage | Adresse de l'esclave | Rd | DonnÃĐes | ArrÊt |
Le protocole I2C est dÃĐfini au niveau bit de la maniÃĻre suivante :
Niveau de pause :
- Le niveau de pause est high.
Condition de dÃĐmarrage :
- La condition de dÃĐmarrage est dÃĐfinie par un flanc descendant sur SDA, suivi d'un flanc descendant sur SCL. Ce signal est univoque et n'apparaÃŪt pas durant une transmission normale.
Condition d'arrÊt:
- La condition d'arrÊt est dÃĐfinie par un flanc montant sur SCL, suivi d'un flanc montant sur SDA. Ce signal est ÃĐgalement univoque et n'apparaÃŪt pas durant une transmission normale.
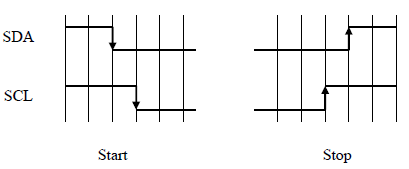
Les bits de donnÃĐes :
- La valeur du signal SDA est fixÃĐe en fonction du bit à transmettre : 0 = low, 1 = high. La validitÃĐ est signalÃĐe avec un flanc montant du signal SCL. La lecture et l'ÃĐcriture des bits de donnÃĐes ont toujours lieu pendant que le signal SCL est haut.
ACK :
- Le bit de confirmation (Acknowledge) veut dire que la rÃĐception est bonne ou que le rÃĐcepteur est prÊt pour des transmissions supplÃĐmentaires. Du point de vue du maÃŪtre, l'esclave doit confirmer chaque octet ÃĐcrit. Du point de vue de l'esclave, le maÃŪtre doit confirmer chaque octet lu. Si ces confirmations n'ont pas lieu, le processus de transmission sera rompu avec le bit d'arrÊt.
NACK :
- Not Acknowledged signale une erreur de transmission ou la fin de la disposition à recevoir.

Dans la Figure 21, le maÃŪtre envoie en premier la condition de dÃĐmarrage, ensuite il envoie l'adresse de l'esclave (1001011) et pour finir le bit R/W. L'esclave doit signaler sa prÃĐsence avec le bit de confirmation. Il est important que le maÃŪtre maintienne le SDA à un ÃĐtat de haute impÃĐdance durant cette phase. Les donnÃĐes peuvent Être transmises aprÃĻs le bit de confirmation (cela n'est pas montrÃĐ dans la figure). La communication est interrompue avec le bit d'arrÊt.
Admettons que l'on veuille connecter un ÃĐmetteur à plusieurs participants avec un bus I2C. Dans ce cas, tous les participants doivent se mettre dans un ÃĐtat de haute impÃĐdance. Certains microcontrÃīleurs peuvent configurer leurs sorties en tri state. Si cela n'est pas possible, il faut configurer les pins SCL et SDA en entrÃĐe.
V-E-3. ImplÃĐmentation▲
Certains microcontrÃīleurs possÃĻdent une interface I2C intÃĐgrÃĐe. La programmation du composant pÃĐriphÃĐrique se rÃĐalise alors avec des registres.
Toutefois, dans certains cas, la rÃĐalisation de l'interface I2C ne peut s'effectuer qu'Ã l'aide de deux ports d'entrÃĐe/sortie numÃĐriques et du code. Cette rÃĐalisation peut nÃĐanmoins varier selon le type de contrÃīleur. Dans ce cas, on commence idÃĐalement par la dÃĐfinition des ports SDA et SCL ainsi que l'ÃĐnumÃĐration des diffÃĐrents codes d'erreurs de la maniÃĻre suivante :
#define SDA P4_2
#define SCL P4_1
typedef enum {I2C_OK, I2C_ACK_ERROR, I2C_BUS_ERROR} I2C_Error;Les fonctions I2C_Init(), I2C_Start(), I2C_Stop(), I2C_Write() et I2C_Read() sont alors implÃĐmentÃĐes par la suite.
Ces fonctions doivent pourvoir accÃĐder aux ports SCA et SCL. Il est ÃĐgalement recommandÃĐ de retourner des messages d'erreurs en cas de problÃĻme.
Exemple de code pour la fonction I2C_Start():
I2C_Error I2C_Start(void) {
I2C_Error error = I2C_OK;
SDA = 1; // Initial state
SCL = 1;
if (!SDA||!SCL){ // Test the bus levels
error = I2C_BUS_ERROR;
}
else {
SDA=0; // Start condition
... // Insert eventually a delay
SCL=0;
}
return(error);
}V-F. Timer▲
V-F-1. Introduction▲
La plupart des microcontrÃīleurs possÃĻdent aujourd'hui un ou plusieurs ÂŦ Timer/Counter Âŧ (français : minuterie/compteur) intÃĐgrÃĐs. Des fonctionnalitÃĐs supplÃĐmentaires, comme celle de ÂŦ Compare/Capture Âŧ, permettent d'ÃĐlargir encore plus les applications de ces contrÃīleurs. Ce chapitre donne un aperçu gÃĐnÃĐral sur ce sujet.
Les applications du Timer/Counter sont les suivantes :
- gÃĐnÃĐration de frÃĐquence d'horloge (ex. dÃĐbit en Baud pour la communication sÃĐrielle) ;
- compteur d'ÃĐvÃĐnements externes ;
- gÃĐnÃĐration de signaux PWM (ou convertisseur D/A) ;
- mesure du temps.
V-F-2. Timer/Counter▲
En gÃĐnÃĐral, des registres de 8 ou 16 bits sont utilisÃĐs dans les modules Timer/Counter. Dans le mode Timer, ces registres sont incrÃĐmentÃĐs pÃĐriodiquement à l'aide de l'horloge interne du systÃĻme. Dans le mode Counter, cette incrÃĐmentation s'effectue en fonction de signaux externes.
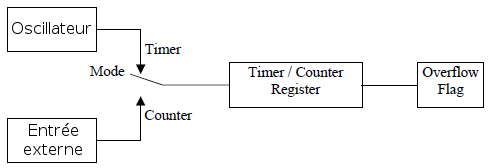
Lorsqu'il y a dÃĐpassement de capacitÃĐ (c'est-à -dire au passage de 0xFFFF à 0x0000 avec un registre de 16 bits), le drapeau (flag) d'overflow est mis à un. Ce dernier peut Être observÃĐ Ã l'aide d'une boucle software (polling) ou il peut gÃĐnÃĐrer une interruption.
Remarque : le contenu du registre Timer est dÃĐcrÃĐmentÃĐ avec certains contrÃīleurs.
V-F-3. Timer avec recharge automatique▲
L'option ÂŦ d'autorechargement Âŧ (anglais : auto reload) du Timer permet de gÃĐnÃĐrer une frÃĐquence d'horloge avec une pÃĐriodicitÃĐ prÃĐdÃĐfinie.
Le mode d'autorechargement permet d'initialiser ÃĐgalement le registre du Timer avec une valeur prÃĐdÃĐfinie.
Cette derniÃĻre est stockÃĐe dans le ÂŦ registre de rechargement Âŧ (anglais : reload register). Ce mÃĐcanisme permet de gÃĐnÃĐrer des frÃĐquences d'horloge de pÃĐriodicitÃĐ variable.
V-F-4. UnitÃĐ comparatrice▲
L'unitÃĐ comparatrice (anglais : Compare Unit) permet de comparer la valeur du registre compteur (Timer Register) avec celle du registre comparateur (anglais : Comparator Register).
L'unitÃĐ comparatrice permet ainsi de gÃĐnÃĐrer des signaux PWM sans demander de la puissance de calcul au CPU. Le signal de sortie du comparateur et l'indicateur de dÃĐpassement (anglais : overflow flag) commutent un port de sortie numÃĐrique. Le latch est rÃĐinitialisÃĐ lorsqu'il y a dÃĐpassement de capacitÃĐ du registre compteur, ce qui met le port au niveau logique 0. Ce mÊme latch est mis à 1 lorsque le compteur du Timer atteint la valeur du registre comparateur, ce qui met le port au niveau logique 1. Ce mÃĐcanisme est illustrÃĐ dans la figure suivante :
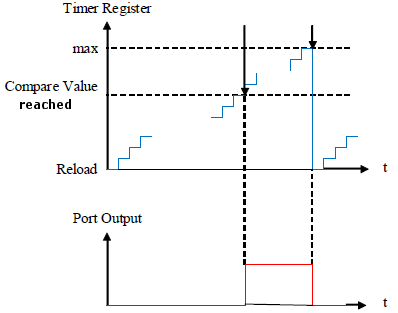
La Figure 25 se base sur un compteur qui compte vers le haut en mode Count-Up. Une variante ici est un compteur qui compte vers le bas en mode Count-Down. La valeur du registre compteur est alors comparÃĐe avec la valeur nulle. Ã chaque passage par zÃĐro, le registre compteur est alors initialisÃĐ avec une valeur de rechargement prÃĐdÃĐfinie.
V-F-5. EntitÃĐ de capture▲
En mode capture, un signal de dÃĐclenchement (anglais : trigger) provoque un transfert de la valeur du registre compteur (Timer Register) dans le registre de capture (Capture Register). Le signal de dÃĐclenchement peut Être fourni soit par la partie logicielle (SW trigger) soit par la partie matÃĐrielle (HW trigger).
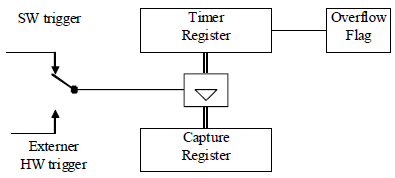
V-G. CAN▲
CAN (Controller Area Network) a ÃĐtÃĐ dÃĐveloppÃĐ en 1981 par la maison Robert Bosch et Intel. Il a ÃĐtÃĐ prÃĐvu pour l'industrie automobile uniquement. Actuellement, CAN s'est ÃĐgalement ÃĐtabli dans l'automation industrielle.
GrÃĒce au grand nombre de chips CAN produits, l'accÃĻs au bus CAN est devenu relativement bon marchÃĐ. On peut les trouver aussi bien comme ÃĐlÃĐments pÃĐriphÃĐriques externes sur des systÃĻmes à microprocesseurs ou comme modules internes à un microcontrÃīleur.
L'organisation d'utilisateurs CiA (CAN in Automation) a dÃĐfini plusieurs standards pour son application dans le domaine de ÂŦ l'automation industrielle Âŧ. Ce qui a conduit à un bon accueil du bus CAN. Le site suivant peut Être consultÃĐ Ã titre d'information : www.can-cia.org.
Avec quelques restrictions, CAN peut Être utilisÃĐ pour des applications temps rÃĐel. Les temps de rÃĐaction sont garantis pour des messages avec un ID de haute prioritÃĐ.
VI. RÃĐfÃĐrences▲
| Nom | Auteur | RÃĐfÃĐrence |
| MISRA-C:2004 (Guidelines for the use of the C language in critical systems) ISBN 978-0-9524156-2-6 |
Misra | [MISRA-C] |
| The Firmware Handbook Jack Ganssle ISBN 978-0-7506-7606-9 |
Newness | [Firmware_Handbook] |
| Embedded Software, The Works Colin Walls ISBN 0-7506-7954-9 |
Newness | [] |
VII. Remerciements Developpez▲
L'ÃĐquipe de rÃĐdaction SystÃĻmes embarquÃĐs tient à remercier Dr Elham Firouzi pour ce tutoriel. Merci ÃĐgalement à F-leb et à Winjerome pour leurs grands efforts fournis dans la gabarisation et la relecture.